Retornar para: Colunas - Fórum PCs

20/03/2006
< Computadores XXVIII: Rótulos >
Na coluna anterior desta série vimos como as listagens dos programas ficam mais fáceis de serem acompanhadas quando se substitui o número em binário que representa a instrução em linguagem de máquina pelo seu mnemônico, uma palavra ou abreviação que ajuda a lembrar o que faz a instrução. Procedendo desta forma, aquela listagem de aparência cabalística que vimos no início da coluna anterior fica assim:

Listagem 1: Substituição de códigos de instrução por seus mnemônicos
Continua cabalística, mas já se pode ter pelo menos uma idéia do que cada instrução faz. Por exemplo, a instrução contida na posição de memória de endereço [00010000]b (esse "b" aí no final, depois do colchete, serve apenas para indicar que o número está expresso em binário) desvia o fluxo do programa (salta) para aquela contida no endereço [00010111]b caso acumulador contenha zero (e se você não entendeu a razão disso, releia a coluna anterior da série). E, para que a listagem do programa volte a ser expressa em linguagem de máquina, basta desfazer a substituição, trocando os mnemônicos pelos correspondentes códigos (numéricos) de instrução.
Mas o problema é que precisamos de alguma coisa que torne os próprios endereços mais compreensíveis. Em outras palavras: da mesma forma que nos referimos às instruções (que são números) usando mnemônicos que nos ajudam a entender o que elas fazem, precisamos de uma forma similar de nos referirmos aos endereços, que nos ajude a entender o que eles contêm. E esta forma consiste simplesmente em atribuir-lhes "rótulos" ("labels", em inglês). Ou seja: em vez de nos referirmos às posições de memória por seus endereços (que nada mais são do que números), passaremos a nos referir a elas por nomes, os "rótulos" que a elas atribuímos. Com uma vantagem: não precisamos atribuir rótulos a todas as posições de memória, somente às mais significativas, aquelas que contêm dados que serão utilizados pelo programa (tenha isto em mente quando discutirmos a noção de "variável") ou que representam pontos importantes no fluxo do programa, como o início da sua rotina principal, pontos de destino de desvios do fluxo do programa (ou "loops") e similares.
As vantagens disto são evidentes: a listagem do programa fica muito mais "limpa", mais fácil de entender, já que apenas passam a constar dela os endereços das posições de memória mais significativas (representadas por seus rótulos), os códigos das instruções e seus parâmetros (que, como no "nosso" conjunto de mnemônicos geralmente são endereços, serão igualmente identificados por seus rótulos). Mas tenha em mente uma diferença essencial entre os "nomes" dos rótulos e dos mnemônicos: enquanto estes são "palavras chave", estabelecidos por quem concebeu a linguagem e não podem ser alterados pelo programador, os rótulos são simplesmente uma forma alternativa do programador se referir a endereços e portanto são atribuídos ("inventados") pelo próprio programador no momento em que ele programa. Explicando melhor: o programador não pode escolher outro mnemônico para substituir, por exemplo, "ACCM" por menos que goste dele, já que ele é uma palavra chave da linguagem. Mas pode escolher o nome que quiser para seus rótulos. Então, no caso da nossa listagem, quando criei o programa eu decidi que rótulos atribuir a que endereços. E resolvi também padronizá-los em quatro caracteres apenas por uma questão de simetria. Rótulos são "inventados" pelo programador na hora em que ele desenvolve o programa e podem ter o tamanho e os nomes que ele desejar (respeitadas as normas da linguagem que estabelece quais caracteres podem ou não ser usados nos nomes dos rótulos, naturalmente).
Isto posto, vejamos como fica nossa listagem atribuindo rótulos aos endereços que precisam deles, eliminando as menções aos demais e substituindo os parâmetros por seus valores ou por seus rótulos:
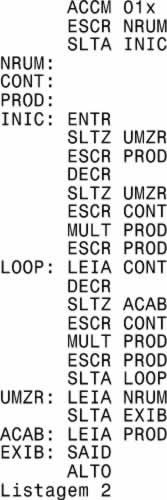
Listagem 2: programa em assembly
Esta listagem corresponde ao programa em assembly (mais tarde discutiremos este termo). Como ela foi gerada? Fácil: primeiro escolhemos os endereços significativos, aqueles que precisarão de um rótulo. O critério é simples: todo endereço ao qual o programa se refira (ou seja, todo o endereço que estiver do lado direito de um mnemônico na listagem 1) precisa de um rótulo. Vamos ver quais são.
A primeira linha da listagem corresponde à instrução ACCM. Ela simplesmente escreve seu parâmetro (aquilo que está á direita do mnemônico) no acumulador. Logo, seu parâmetro não é um endereço, é um número (para ser explícito, o número "um", expresso por [00000001]b em binário e por 01x em hexadecimal – e nesse último caso o "x" à direita do número serve apenas para informar que ele está expresso em hexadecimal). Não sendo um endereço, este parâmetro não precisa de um rótulo.
Vejamos os demais. A segunda linha contém a instrução ESCR. Ela escreve o conteúdo do registrador na posição de memória indicada pelo seu parâmetro. Logo, seu parâmetro é um endereço, é referido pelo programa e portanto precisa ser substituído por um rótulo. Que endereço é esse? Veja, na listagem 1, que se trata do endereço [00000011]b. Vamos atribuir a ele o rótulo "NRUM" (por que "inventei" justamente este nome? Ora, logo você verá que durante todo o tempo de execução do programa esta posição de memória armazenará o número "um"; portanto escolhi para ela um rótulo que me lembre o que ela armazenará: NRUM, ou seja, NúmeRo UM). Então na nova listagem toda referência ao endereço [00000011]b será substituída por NRUM.
A terceira linha contém a instrução SLTA, um salto incondicional. Para onde? Para o endereço representado por seu parâmetro. Que, portanto, sendo um endereço, merece um rótulo. Que endereço é este? É o [00000110]b (veja na listagem). Mais adiante, quando interpretarmos o programa, você verá que este endereço corresponde ao início da rotina do programa. Então vamos batizá-lo de "INIC". E na nova listagem toda referência ao endereço [00000110]b será substituída por INIC, que lembra INICio.
Agora, examine novamente a listagem em assembly: suas três primeiras linhas não contêm coisa alguma no espaço destinado ao endereço. Por que? Ora, porque esses endereços não são significativos, portanto não merecem rótulo. E como estão em ordem crescente, sempre começando pelo zero, os números que os representam são desnecessários (eu sempre saberei quais são, basta contar a partir do zero: [00000000]b, [00000001]b e [00000010]b) e portanto posso removê-los da listagem.
Já na próxima linha, a quarta, o local do endereço contém o rótulo NRUM (seguido de dois-pontos; já voltaremos a isso). Por que? Ora, para identificar um endereço importante, já que o programa se refere a ele tanto na primeira instrução quanto mais adiante (veja na listagem a referência a ele quase no final do programa).
Como tal posição de memória cujo endereço é [00000011]b e cujo rótulo é NRUM não conterá uma instrução nem um parâmetro, apenas um valor fixo (o número "um") e como este valor ainda não foi escrito nela (o será "em tempo de execução", ou seja, assim que a primeira instrução do programa for executada), a linha a ela correspondente na listagem não precisará conter mais nada, apenas o rótulo.
Quanto ao "dois-pontos" depois do rótulo: trata-se de uma convenção da linguagem. Em uma listagem, quando o rótulo (a palavra que serve para substituir o endereço) está à esquerda do mnemônico, ou seja, identificando a posição de memória, ele é seguido de dois pontos para mostrar que a posição é aquela. Já quando ele estiver à direita do mnemônico, ou seja, funcionando como um parâmetro e se referindo à uma posição de memória, não se usa o dois-pontos.
Vejamos agora as duas linhas seguintes, cujos rótulos são, respectivamente, CONT e PROD. Como logo veremos a primeira identifica uma posição de memória que conterá um valor que se alterará durante a execução do programa e que serve para "contar" os passos de uma determinada rotina (e cujo rótulo CONT deriva do nome CONTador) e a segunda conterá outro valor que também será alterado durante a execução do programa e que corresponde ao produto de dois fatores (e cujo rótulo indica isto: PROD de PRODuto). Essas linhas, juntamente com a anterior, correspondem a posições de memória que durante toda a execução do programa armazenarão dados (que variam durante a execução, portanto "variáveis"), não instruções. Por isso basta que constem na listagem com seus rótulos, que substituem os endereços.
A próxima linha, identificada pelo rótulo INIC, corresponde ao início da rotina do programa (as anteriores foram apenas uma "preparação" reservando posições de memória para as variáveis; voltaremos ao assunto mais adiante). Ela contém apenas o rótulo que a identifica e o código da instrução, ENTR, uma instrução que não usa parâmetro, apenas recebe o dado da entrada padrão.
Vejamos as próximas. A seguinte contém apenas o código da instrução SLTZ e seu parâmetro, "UMZR", um endereço situado mais adiante. A próxima, contém a instrução ESCR e seu parâmetro. E assim sucessivamente. Nenhum dos endereços das posições de memória correspondentes é referido pelo programa (ou seja, é usado como parâmetro). Portanto não precisam de rótulos: seus endereços são números que seguem em ordem crescente e que não precisam aparecer na listagem. A próxima posição de memória a merecer um rótulo é LOOP, bem mais adiante (logo veremos porque). E assim prossegue a listagem assembly até o final. Sem um único número em binário. O que inegavelmente a torna muito mais fácil de ser compreendida.
Agora pense um pouco: como fazer para reconstituir a listagem em linguagem de máquina, apresentada na coluna anterior a partir da listagem correspondente em assembly, exibida na listagem 2? Nada mais simples: basta substituir cada mnemônico por seu código de instrução, cada rótulo pelo número do endereço correspondente e preencher os claros com endereços em ordem crescente na coluna da esquerda (a dos endereços) e com zeros na da direita (para completar as instruções que não usam parâmetros). Portanto, ainda há uma correspondência biunívoca (de um-para-um) entre ambas as listagens. Por exemplo, a linha da listagem assembly:
LOOP: LEIA CONT
na listagem em linguagem de máquina fica:
00001110 1000 00000100
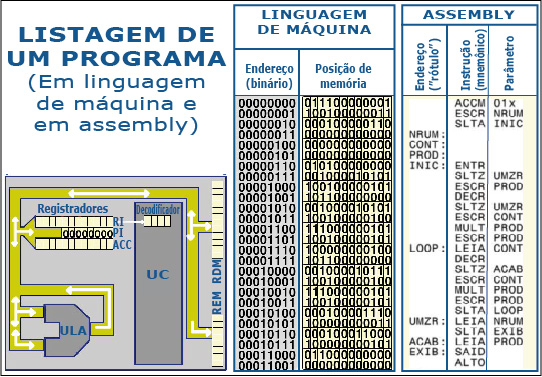
Listagens em Linguagem de Máquina e em assembly
Para verificar como esta correspondência é exata, recorra á figura acima. Ela mostra lado a lado as listagens do programa em linguagem de máquina e em assembly. Veja como cada rótulo, esteja ele à direita ou à esquerda do mnemônico, corresponde ao mesmo endereço na linguagem de máquina.
Como você vê as listagens são essencialmente iguais, apenas muda a forma de se referir às mesmas coisas: mnemônicos x códigos de instrução e rótulos x endereços.
Portanto, a operação de converter uma listagem em assembly pela listagem correspondente em linguagem de máquina consiste apenas em substituir mnemônicos e rótulos por números em binários (e mais tarde veremos, na prática, quem faz isso).
Não obstante a listagem assembly é muito mais fácil de entender. E para que fique ainda mais, falta apenas acrescentarmos um ingrediente: os "comentários".
Comentários, em listagens assembly, são o que o próprio nome indica: comentários incluídos pelo programador enquanto cria o programa para explicar a finalidade de cada instrução ou posição de memória reservada para as "variáveis". Eles são escritos à direita da listagem assembly, no final de cada linha, e são simplesmente desprezados no momento de converter a listagem para linguagem de máquina. Servem apenas para orientar quem examinar a listagem futuramente (em geral o próprio programador, que muitas vezes esquece da razão pela qual determinadas instruções foram incluídas). Comentários não são obrigatórios, mas o bom senso recomenda que eles sejam sempre incluídos em listagens assembly.
Vejamos como fica nossa listagem depois de incluídos os comentários.
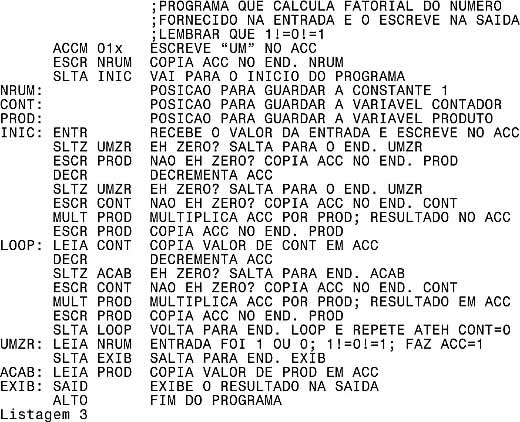
Listagem 3: programa assembly comentado
Agora, sim, ficou fácil entender o que o programa faz. Mesmo porque sua finalidade se explicita logo nos comentários iniciais (comentários no início da listagem precedidos por ponto-e-vírgula antes do primeiro endereço de memória, que geralmente servem para indicar a finalidade do programa e fazer algumas observações importantes): calcula o fatorial de um número fornecido no dispositivo de entrada padrão (provavelmente o teclado) e exibe o resultado na saída padrão (provavelmente o vídeo). Para quem não lembra: o fatorial do número "n" é (n! = n x n-1 x n-2 ... 3 x 2 x 1) ou seja, 6! = 6 x 5 x 4 x 3 x 2 x 1 = 720 e por definição o fatorial de "zero" é "um".
Mas vamos interpretar o programa usando a listagem.
Até o rótulo INIC o programa apenas "prepara" as coisas: reserva espaço para as variáveis PROD e CONT (a primeira armazenará os produtos intermediários e o final, a segunda armazenará o fator que vai sendo decrementado e que conta os desvios), escreve a constante "um" na posição NRUM e salta para o início da rotina de teste e cálculos.
De INIC até LOOP o programa testa se a entrada foi "um" ou "zero". Se foi, não precisa calcular nada, já que em ambos os casos o fatorial vale "um". Basta então saltar para o endereço UMZR, escrever o valor "um" armazenado em NRUM no ACC, exibi-lo na saída e terminar o programa.
Se a entrada não foi nem "um" nem "zero", o programa inicia os cálculos. Multiplica o valor de PROD (onde a entrada foi copiada) por CONT (que contém a entrada decrementada), ou seja, efetua o primeiro produto do fatorial, armazena o resultado em PROD e retorna para o endereço LOOP, decrementando novamente CONT. Quando CONT chegar a zero, os produtos acabaram e o fatorial está armazenado em PROD. Então basta saltar para o endereço ACAB, transcrever o resultado no ACC, exibi-lo na saída padrão e encerrar o programa.
Fácil, nénão?
Eu não disse que programar em assembly é mais simples do que parece?
Pois bem, agora que você é um exímio programador Assembly, só falta "fechar" o assunto com alguns comentários interessantes sobre a linguagem e as noções de variáveis e ponteiros.
Mas esta coluna já está demasiadamente longa, deixemos para a próxima da série. Até lá.