< Coluna em Fórum PCs >

24/03/2008
<
A nova arquitetura Intel II: >
< novo cache e Quick Path >
|
< Coluna em Fórum PCs >
|
|
|
|
24/03/2008
|
<
A nova arquitetura Intel II: > |
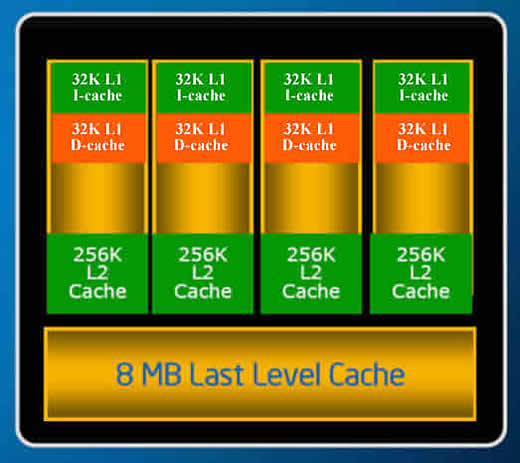
A coluna anterior, na qual discutimos, ainda que superficialmente, as principais inovações introduzidas pela Intel em sua nova arquitetura de microprocessadores que equipará a família Nehalem, terminou afirmando que nesta examinaríamos as alterações feitas no cache e na estrutura de interconexão. Pois vamos a elas. Começando por afirmar que tanto uma quanto a outra foram bastante radicais. Senão, vejamos. Em março de 2006, logo após a tecnologia “Smart Cache” ter sido apresentada na edição daquele ano do IDF de San Francisco, EUA, publiquei uma coluna descrevendo no que ela consistia e discutindo as principais mudanças que a Intel então introduziu no cache de seus processadores. A coluna “IDF Spring 2006: Smart Cache”, além de destrinchar a nova tecnologia, começava examinando o conceito de “cache”, suas vantagens, utilização e hierarquia (múltiplos níveis de cache), abordando finalmente o conceito de compartilhamento de cache. Como estes conceitos são a base do que será discutido abaixo, caso surjam dúvidas sobre eles sugiro uma consulta ao artigo. Que, embora velho de dois anos, continua atual. Pois bem: um dos melhoramentos que a família Nehalem incorporará será justamente a inclusão de um terceiro nível de cache, o cache L3 (incidentalmente: isto só é novidade para as famílias de processadores Intel; a AMD já adota em seus processadores de última geração essencialmente a mesma estrutura de cache que a Intel usará no Nehalem). Tentando ser breve: os microprocessadores Nehalem continuarão usando a tecnologia "Smart Cache", porém além dos caches interno L1 e L2 (este, agora não mais compartilhado), seus membros incluirão ainda no interior do próprio microprocessador um cache L3, de terceiro nível, cuja capacidade pode chegar até 8 MB, compartilhado (acessível a todos os núcleos). Este novo cache L3 é "inclusivo". Um cache inclusivo é aquele que pode conter dados já armazenados nos caches hierarquicamente superiores. Ou seja: mesmo que uma determinada linha de memória já disponha de uma cópia nos caches L1 ou L2, ela poderá ter mais uma cópia incluída no cache L3. Parece desperdício, pois não? E, em um sistema de núcleo único, seria mesmo (se a busca é feita sempre em ordem hierárquica, não faz sentido copiar no cache L2 algo que já está contido no L1 nem copiar no cache L3 algo que já está contido em L2). Mas convém não esquecer que a microarquitetura Nehalem foi concebida para ser usada principalmente em processadores de múltiplos núcleos. E se uma cópia de uma determinada linha de memória estiver contida no cache L1 de um dos núcleos, ela apenas será imediatamente acessível a este núcleo. E caso ocorra uma falha de acesso ao cache L3 (“cache miss” ou tentativa de acesso a uma posição de memória cuja cópia não esteja nele contida), se o cache L3 for “exclusivo” (ou do tipo que se abstém de copiar linhas de memória já contidas nos caches de nível hierárquico superior), ou será necessário fazer uma varredura em busca da cópia nos caches L2 e L1 de cada núcleo, ou se terá que acessar diretamente a MP. O que, em ambos os casos, representa uma brutal perda de tempo. Portanto, se o acréscimo de um nível de cache representa um enorme ganho de desempenho, o fato deste cache ser inclusivo representa ganho maior ainda. A hierarquia de cache do Nehalem terá então três níveis. Os níveis L1 e L2 serão semelhantes aos da família Penryn com exceção do fato de que o cache L2 não mais será compartilhado. O cache L1, de primeiro nível, situado no interior de cada núcleo, terá uma capacidade de 64KB dos quais 32KB serão usados apenas para instruções e os 32KB remanescentes para dados. O cache o L2, de 256 KB para cada núcleo, será usado tanto para dados como para instruções. Já o novo cache L3, de até 8Mb por processador, será totalmente inclusivo e compartilhado entre todos os núcleos de tal forma que, em situações particulares, qualquer aplicação de intensivo acesso à memória poderá, se necessário, se assenhorear de todo o cache L3. Veja, na Figura 1 (como as demais desta coluna, retirada da apresentação de “slides” obtida do conjunto de “slides” apresentado pela Intel na “conference call” citada na coluna anterior) como fica a estrutura hierárquica do cache de um microprocessador da família Nehalem com quatro núcleos.
Ainda sobre cache: toda a linha Nehalem incluirá um novo cache de segundo nível hierárquico para armazenar um “Translation Lookaside Buffer” (TLB) adicional de 512 entradas (o TLB acelera o desempenho do hardware de gerenciamento de memória armazenando as tabelas de conversão de endereços físicos de memória para endereços usados nos sistemas virtualizados; os processadores atuais já usam TLB, porém de um único nível hierárquico). Tecnologia Quick Path. Nos tempos heróicos do velho PC as coisas eram relativamente simples. O processador 8088 que o equipava era lento, é verdade. Mas o acesso à memória principal era ainda mais lento. Portanto, bem ou mal, as coisas se equilibravam. Evidentemente, nos 27 anos de existência da linha PC, tanto o microprocessador quanto as memórias evoluíram. O problema é que a evolução do primeiro foi muitas vezes mais rápida que a das últimas. E logo o acesso à MP se tornou o grande gargalo do processamento: os processadores eram capazes de receber cada vez maiores quantidades de dados e instruções e processá-los cada vez mais depressa, mas a MP não conseguia fornecê-los com a rapidez necessária. A forma de a indústria minimizar o problema foi a implementação de caches internos cada vez maiores e mais hierarquizados e, sobretudo, a criação do “barramento frontal”, ou “Front Side Bus” (FSB), uma conexão externa, bidirecional, por onde os dados e instruções fluem entre UCP e MP e se constitui na espinha dorsal entre o processador, o controlador da memória principal ("memory controller hub", localizado no próprio FSB) e os demais barramentos (AGP, PCI, etc.). Para que possa ser compatível com a rapidez dos acessos à MP, o FSB opera em freqüência menor que a do processador. Esta diferença na freqüência de operação fez com que o FSB se tornasse o grande “gargalo” do processamento dos sistemas modernos. Um gargalo que se tornou ainda mais estreito com a difusão dos sistemas multiprocessados, onde não somente os diversos processadores devem competir pelo uso do controlador da memória situado no FSB como também devem manter uma constante troca de informações entre eles para assegurar a coerência da memória (isto se chama “snoop traffic”; “snoop” é um termo inglês que tem, entre outras, a acepção de “farejar”; é como se os diferentes processadores da mesma placa-mãe permanecessem “farejando” uns aos outros para atualizar eventuais alterações que os demais tenham feito na MP para que cada um deles possa ter uma imagem da MP “coerente” com a dos demais). Pois bem: até aqui vínhamos discutindo os aperfeiçoamentos introduzidos pela Intel na arquitetura interna dos processadores da família Nehalem, todas elas voltadas para o aumento do desempenho com baixo consumo de energia. Mas quanto mais se aumenta o desempenho dos processadores, maior se torna a diferença entre a rapidez de processamento e a de acesso à MP. Portanto, para que se possa usufruir das melhorias aportadas por uma nova arquitetura interna de processador é preciso que ela seja complementada por uma arquitetura de interconexão igualmente aperfeiçoada. Pois a interconexão atual, baseada no FSB, definitivamente não é mais adequada aos tempos de processadores de núcleos múltiplos e, sobretudo, de sistemas multiprocessados. Isto levou a Intel a conceber uma nova estrutura de interconexão, cujo protótipo era conhecido pelo nome de “Common System Interface” (CSI) e que acaba de se rebatizada de "Quick Path". Cuja filosofia é simples: se o gargalo é o FSB, então remova-se o FSB. Também isto não é novidade. A novidade é que pela primeira vez está sendo usada nos microprocessadores da Intel, já que ela foi concebida nos moldes da arquitetura externa de servidores de alto desempenho que utilizam sistemas multiprocessados (com mais de um processador na placa-mãe; não confundir com sistemas multinucleares, que usam um único processador com diversos núcleos) e nas chamadas “máquinas de grande porte”. De fato, embora sua utilização em microcomputadores seja recente, ela vem sendo utilizada há anos nas máquinas “de grande porte” onde é conhecida por NUMA (“Non-Uniform shared Access”, ou acesso compartilhado não-uniforme). A idéia básica consiste essencialmente em tratar a MP como um grande campo de endereços escalável e compartilhado entre os diversos processadores. Com ela, cada processador terá seu campo de memória dedicado que, não obstante e caso necessário, pode ser acessado pelos demais (por isso é compartilhado). A mudança é radical e exigirá que todo um novo padrão de “chipset” (conjunto de circuitos auxiliares da placa-mãe) seja concebido. Isto porque a idéia sobre a qual se apóia a concepção da arquitetura de interconexão “Quick Path” é remover o controlador da memória do FSB e trazê-lo para o interior do próprio processador (agora, examine novamente a Figura 1 da coluna anterior e entenda porque eu ressaltei que não se deveria estranhar a inclusão de um controlador de memória no interior do processador). O resultado prático disto é eliminar o FSB (e, conseqüentemente, o gargalo por ele formado). Trazendo o controlador da memória para o interior do processador consegue-se aumentar significativamente a rapidez com que os dados fluem do cerne do processador até o controlador de memória. Além disto, em vez de "enxergarem" um único "espaço de endereçamento" de memória, cada processador recebe seu trecho dedicado de MP que ele mesmo controla. E, finalmente, a ligação entre MP e o controlador da memória (agora dentro do processador) é feita por um barramento muito rápido, de alta freqüência de operação, que troca “pacotes” de dados e aumenta a confiabilidade das transações aplicando a eles uma verificação cíclica de redundância (CRC, ou “Cyclic Redundacy Check”). Note-se que mesmo com seus espaços dedicados de memória, em casos de aplicativos que façam uso intensivo da memória um processador pode necessitar de acesso ao trecho de memória dedicado a outro. Além disto este acesso é necessário para manter a coerência. Mas ele não mais sobrecarregará a conexão entre processador e MP, já que se fará através de uma estrutura independente denominada “Quick Path Interconnect”, que interligará diretamente todos os processadores de um dado sistema (veja Figura 2).
Segundo a Intel, a maior vantagem desta concepção é que a comunicação entre processador e MP passará a ser "ponto-a-ponto", acabando com o gargalo de um único barramento e controlador de memória compartilhado por todos os processadores que precisariam disputar entre si o acesso. Ela também elimina o tráfego entre processadores através do barramento de conexão com a memória, já que todo o “snoop traffic” passa a ser feito diretamente entre processadores através da “Quick Path Interconnect”. Tudo isto, combinado com a inclusão de um cache de terceiro nível e grande tamanho, deverá implicar um notável incremento na rapidez de acesso à MP nos processadores da família Nehalem usando a interconexão Quick Path. De fato, durante a “conference call”, Pat Gelsinger mencionou que cada interconexão Quick Path será capaz de sustentar uma taxa de transferência da ordem de 25GB/s, cerca de três vezes maior que a alcançada pela interconexão tradicional via FSB. Veja, no lado esquerdo da Figura 2, como é feita a interconexão via Quick Path em um sistema multiprocessado (no caso, com dois microprocessadores). Cada processador está ligado diretamente aos circuitos de MP a ele dedicados sem a necessidade de qualquer circuito de controle externo, já que o controlador da memória está “embutido” no processador. Repare que os dois processadores estão interligados. Trata-se da Quick Path Interconnect, que além de manter a coerência da memória, permite que em caso de necessidade um processador tenha acesso ao espaço de memória dedicado ao outro. Note que não há mais “barramento frontal” (FSB): os dois processadores estão ligados diretamente a dois controladores de Entrada/Saída, um deles para controlar diretamente os dispositivos de alto desempenho que obedecem ao padrão PCI Express e o outro (ICH) para os demais barramentos externos (PCI, AGP, etc.). Evidentemente esta alteração acaba por afetar também sistemas com um único processador. Mas neste caso a diferença essencial será o fato de o controlador da memória passar a ser parte integrante do microprocessador e não mais do FSB, como pode ser visto no diagrama à direita da Figura 2. Ainda segundo Gelsinger, cada soquete de microprocessador comportará três canais de conexão direta entre UCP e MP (veja Figura 2) e cada canal pode receber até três módulos de memória tipo DIMM (“Dual Inline Memory Module”). Poderão ser usados inicialmente módulos de memória tipo DDR3 com freqüências de operação de 800MHz, 1066MHZ ou 1333MHz e, no futuro, com freqüências maiores quando estiverem disponíveis. Será um elo de latência muito baixa (em virtude de o controlador operar no interior do processador) e de alta taxa de transferência (devida ao grande número de canais e das elevadas freqüências suportadas). Além de tudo isto, a arquitetura Quick Path traz uma interessante característica adicional: permite ligação “à quente”. Quer dizer: em um sistema que use processadores da família Nehalem com interconexão Quick Path será possível acrescentar uma placa com um processador adicional sem desligar a máquina... A família de processadores com arquitetura Nehalem e estrutura de interconexão Quick Path abrangerá os futuros modelos de processadores para micros de mesa e portátil, além dos servidores atualmente baseados em processadores da linha Xeon e Itanium (neste caso,a microarquitetura equivalente à Nehalem para o Itanium recebeu o nome de código Tukwilla; seu o primeiro modelo terá quatro núcleos, usará 30MB de cache interno em camada de silício de 45nm e comportará dois bilhões de transistores). A Intel garante que os principais fabricantes de circuitos auxiliares (“chipset”) já aderiram à nova arquitetura externa Quick Path. E, mais que isso: garante que em 2009/2010 a família Nehalem será sua primeira geração de microprocessadores a experimentar a tecnologia de fabricação em camada de silício de 32nm empregando a tecnologia “Hi-K Metal Gate Silicon”. Pois bem: agora que já conhecemos alguma coisa sobre a arquitetura interna dos microprocessadores da família Nehalem e sobre a arquitetura externa que os suportará, Quick Path, poderemos voltar ao tema da “escalabilidade em nível de projeto” que mencionamos na coluna anterior e que prometemos abordar novamente quando dispuséssemos dos conhecimentos necessários.
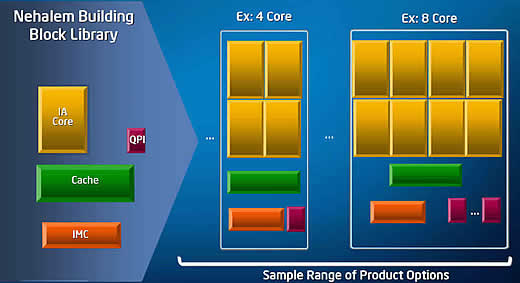
Repare no lado esquerdo da Figura 3. Nele são mostrados separadamente os componentes do interior de um microprocessador da família Nehalem. São eles: o núcleo (“IA Core”), o controlador da estrutura Quick Pack (QPI), o conjunto de cache e o controlador integrado de memória (IMC). Esses componentes são mostrados individualmente por uma razão simples: eles foram concebidos para manter suas características de funcionamento não importa como venham ser interligados. E como se trata de uma decisão tomada durante a concepção dos circuitos, eles podem ser interligados de diferentes maneiras e ainda assim manter sua integridade. Em suma: podem ser usados, em nível de projeto, como se fossem elementos de um conjunto de “blocos de montagem” (“building blocks”). Sendo assim, a Intel pode usar os componentes para projetar diferentes modelos de processador, cada um deles voltado para preencher um determinado nicho de mercado com suas necessidades específicas de capacidade de processamento. Desta forma a Intel pode projetar e fabricar um microprocessador da família Nehalem relativamente simples, como o mostrado no centro da Figura 3, com quatro núcleos, cache, controlador integrado de memória e um único controlador Quick Path, ou um microprocessador muito mais complexo e poderoso como o mostrado no lado direito da Figura 3, com oito núcleos, cache, controlador integrado de memória e tantos controladores Quick Path quantos necessários para uso em sistemas multiprocessados. É a isto que a Intel se refere quando menciona a “escalabilidade em nível de projeto”. B. Piropo |