< Coluna em Fórum PCs >

17/08/2009
< Nova Estrutura da Marca Intel VII: Nehalem, o estado da arte >
|
< Coluna em Fórum PCs >
|
|
|
|
17/08/2009
|
< Nova Estrutura da Marca Intel VII: Nehalem, o estado da arte > |
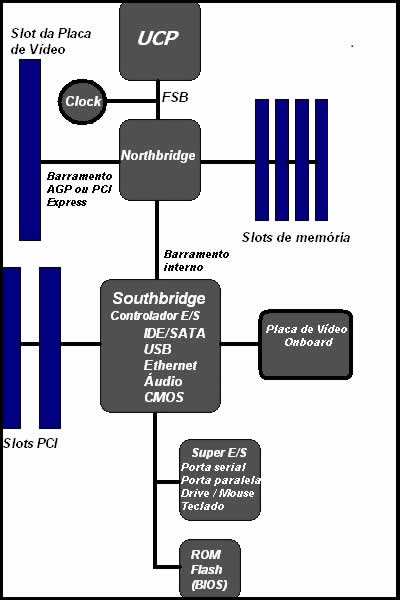
Há quem pense que o fator mais importante para o sucesso no mercado de tecnologia é não cometer erros. Pois estão enganados. Mesmo porque, para quem é obrigado a lançar continuamente novos produtos para satisfazer as necessidades – e voracidade – do mercado, jamais cometer erros é missão impossível. Então, o fator mais importante para o sucesso neste mercado não é evitar os próprios erros, mas aprender com eles. E, nisso, a Intel é inexcedível. Está aí a arquitetura Nehalem que não me deixa mentir. Originalmente, o nome (que, como sempre, replica o de um rio da Costa Oeste dos EUA) foi cunhado para designar a sucessora da arquitetura Netburst. Mas, dadas as limitações desta última, acabou sendo usado para batizar uma arquitetura completamente diferente. Falemos sobre ela. Os primeiros processadores baseados na arquitetura Nehalem serão (ou melhor: já estão sendo) fabricados usando a tecnologia de gravação em camada de silício de 45 nm, adotada nos mais modernos representantes da arquitetura Core (que usam a revisão Penryn). E espera-se para breve novas revisões com espessura de 32 nm. A Nehalem foi concebida desde o início para um universo onde núcleos múltiplos serão o denominador comum. Por isso, desde a concepção, estão programados em prazo relativamente curto os lançamentos de unidades de dois, quatro, seis ou oito núcleos. Em sistemas deste tipo, o gargalo seria o barramento frontal (FSB, de “Front Side Bus”). E não é preciso dominar a tecnologia de microprocessamento para entender o porquê desta afirmação. Senão vejamos. O bom e velho 8086 que equipava o primeiro IBM PC se comunicava com a memória e com os periféricos usando um único conjunto de condutores elétricos e circuitos de controle. Ou seja: mesmo sem o saber, foi pioneiro naquilo que anos depois passou a ser conhecido como “barramento local”. O que não era prova de modernidade, muito pelo contrário. Na verdade naquele tempo tudo era tão lento que a mesma frequência de operação do processador, parcos 4,77MHz, poderia ser adotada tanto para trocar dados com as placas controladoras dos dispositivos de entrada e saída (E/S) “espetadas” nos conectores da placa-mãe (os “slots”), quanto para se comunicar com a lerda memória principal. Mas logo se percebeu que isso não poderia durar para sempre e já a segunda geração, representada pelo 80286, passou a adotar frequências diferentes, uma mais lenta para “conversar” com os dispositivos de E/S e outra mais rápida (que, no início, era a mesma do processador) para intercambiar dados com a memória principal (MP). E não custou muito para que, nos tempos do i486, também a frequência de operação do processador se tornasse independente daquela que regia a comunicação com a MP. A partir de então, o processador operava com a maior frequência que seus fabricantes pudessem alcançar, os dispositivos de E/S com a frequência determinada por seu protocolo de troca de dados (por exemplo: PCI a 33 MHz, AGP a 66 MHz, ISA a 12 MHz) e a frequência da comunicação com a MP dependia do tipo de memória adotado (mas era sempre um submúltiplo da frequência da UCP). Complicou? Pois vamos simplificar. Considere que a placa-mãe de seu computador é composta por três elementos principais que se intercomunicam. Os elementos são o microprocessador (ou UCP, Unidade Central de Processamento), os dispositivos de entrada e saída (E/S, compostos por tudo aquilo que se comunica com o computador, incluindo vídeo, teclado, rede e o que mais nele estiver espetado, o que engloba a memória secundária formada pelos discos rígidos, óticos, “pen-drives” e assemelhados) e a memória principal (MP). A intercomunicação é feita através de pulsos elétricos que trafegam em um conjunto de condutores elétricos que, juntamente com seus circuitos de controle, chamam-se “barramentos”. Quanto mais rapidamente os pulsos elétricos são emitidos (ou seja, quanto maior a frequência de operação do barramento que os conduz), mais depressa se dá a comunicação. Ora, se nós classificarmos os elementos de acordo com sua rapidez, o primeiro lugar, disparado (termo usado com rara propriedade), caberá ao processador, que atualmente opera na escala dos GHz (bilhões de ciclos por segundo). E os mais lentos, sem dúvida, serão os dispositivos de E/S, como teclado, escâner, vídeo e rede, que se comunicam em pulsos emitidos na escala das dezenas de MHz (milhões de ciclos por segundo). No meio, fica a MP, cujos dados fluem com frequências da ordem de centenas de MHz. Então fica fácil entender a existência de dois barramentos. Um, mais lento (cuja frequência varia de acordo com o protocolo adotado, mas se situa na casa das dezenas de MHz), que conecta o processador com os dispositivos de E/S e que, tradicionalmente, é referido como “southbridge” (ponte sul). E outro, cuja frequência varia com o tipo e qualidade da memória adotada mas que se situa na casa das centenas de MHz, usado exclusivamente para se comunicar com a memória. Este último, também conhecido como “northbridge” por ser o mais importante e se situar à frente dos demais, é o barramento frontal, ou FSB. Então, reduzindo tudo à sua expressão mais simples, “barramento frontal” é a via de comunicação entre microprocessador e memória principal. Quando a UCP precisava se comunicar com um dos periféricos, acionava os circuitos de controle localizados no trecho de barramento correspondente (a “southbridge”) e enviava ou recebia os dados – no último caso, sempre atendendo a uma solicitação – ou “interrupção” – emitida pelo periférico que precisava da atenção da UCP. Por outro lado, quando se tratava de comunicação entre UCP e MP, era sempre a UCP que acionava os circuitos de controle da memória e fazia os dados fluírem entre ela e os chips de memória. Simples assim. Simples e funcional, diga-se de passagem, pois permitia não somente que a comunicação entre memória e processador se estabelecesse via “northbridge” tão rapidamente quanto os processos de fabricação de UCPs, circuitos de memória e seus controladores o permitissem – uma coisa essencial para um bom desempenho do sistema – como também que a comunicação entre UCP e periféricos fosse feita via “southbridge” usando o protocolo adequado a cada tipo de periférico e nas frequências por eles exigidas – sempre menores que a usada na “northbridge”. Veja, na Figura 1, um esquema, obtido na Wikipedia, das conexões de uma UCP com os barramentos de E/S (“southbridge”) e frontal (FSB ou “northbridge”). Nela, convém atentar para alguns detalhes. O primeiro é que ela representa o caso geral, onde a ligação entre “southbridge” e UCP se faz através da própria “northbridge”. O segundo, é que – também neste caso – a “northbridge” não se encarrega apenas da comunicação com a UCP, mas também com um segundo barramento de alto desempenho – no caso o AGP ou PCI Express, usado predominantemente para vídeo. E, finalmente, que no que diz respeito é o que mais interessa, é que – embora não apareça explicitamente na figura – em um esquema como esse o controlador de memória não se localiza na UCP mas está incorporado aos circuitos de controle da própria “northbridge”.
Este esquema funcionou muito bem – ou, pelo menos, bastante razoavelmente – por duas décadas. Mas tem um inconveniente óbvio: por ser a única comunicação entre a memória e a UCP, nas situações em que é preciso trocar dados muito rapidamente, o FSB acaba se tornando um “gargalo”. Gargalo que, por razões óbvias, tem seus efeitos ampliados na medida que aumenta o número de núcleos do processador, posto que para garantir um bom desempenho é essencial que todos eles acessem a memória o mais rapidamente possível. A Intel procurou contornar este problema aumentando a capacidade dos caches internos de seus processadores. “Caches”, como sabemos, são trechos de memória muito rápida situados entre a fonte e o destino dos dados, onde são feitas cópias de parte dos dados contidos na fonte para acelerar a leitura caso estes dados venham a ser acessados (pois a cópia contida no cachê é lida diretamente muito mais depressa). Então, a cada acesso, verifica-se se o dado está ou não no cache. Se estiver (e a probabilidade de que esteja se situa na casa dos 99%), a leitura é feita imediatamente do próprio cache. Se não estiver, o dado é lido na fonte (no caso, a MP, bastante mais lenta) e copiado no cache para facilitar uma eventual nova leitura. Tudo isto fez com que os caches internos dos processadores Intel viessem crescendo a ponto de se tornarem gigantescos (o Core 2 Quad Q9100 alimenta seus quatro núcleos com um cache interno de 12 MB). Um alvitre que funciona dentro de certos limites pois, na medida que se aumenta a capacidade do cache, chega-se a um ponto que a perda de tempo para verificar se há nele uma cópia do dado acaba por deitar a perder o ganho de tempo na leitura. Logo, o recurso do aumento do cache tem um limite e a Intel já estava chegando a ele. A AMD, espertamente, procurou outro caminho e tomou providências para resolver este problema desde os idos de 2001 usando uma tecnologia que batizou de HyperTransport. O HyperTransport não é apenas uma tecnologia para substituir o FSB. É muito mais que isso. Segundo a < http://en.wikipedia.org/wiki/HyperTransport > Wikipedia, trata-se de “uma conexão ponto-a-ponto bidirecional, serial/paralela, de pequena latência e alta taxa de transferência de dados” que pode ser usada para qualquer tipo de conexão entre elementos. Mas no caso dos chips da AMD, a grande “sacada” foi utilizá-la para a troca de dados entre a MP e a UCP, substituindo (e, portanto, eliminando o gargalo d’) o barramento frontal. E como se trata de uma comunicação do tipo “ponto-a-ponto”, seu uso obrigou a AMD a trazer os circuitos de controle da memória para o interior do próprio microprocessador. Isto permitiu uma troca de dados bidirecional entre UCP e MP capaz de transferir até 51,2 GB/s (GigaBytes por segundo), 25,6 em cada sentido. A AMD vem usando esta tecnologia há anos em seus chips das famílias Opteron, Athlon 64, Sempron 64, Turion 64 e Phenom. Mas esta série é sobre a nova estrutura da marca Intel, portanto melhor voltar a ela. Falávamos, então, na arquitetura Nehalem. E o que tem ela a ver com o HyperTransport? Bem, com o HyperTransport propriamente dito, uma tecnologia patenteada e gerida por um consórcio, nada a ver. Mas com o que ele significa, a Nehalem tem tudo a ver. Porque a principal novidade da nova arquitetura é justamente a eliminação do barramento frontal, exatamente o que faz o HyperTransport, porém usando uma tecnologia proprietária da Intel, que foi batizada de Intel QuickPath Interconnect (ou “QuickPath”, ou ainda QPI). Que, ainda segundo a < http://en.wikipedia.org/wiki/Intel_QuickPath_Interconnect > Wikipedia, nada mais é que “uma interconexão ponto-a-ponto para ser usada em microprocessadores desenvolvida pela Intel para concorrer com o HyperTransport” (isto é uma tradução livre do verbete da Wikipedia). Quick Path Interconnect é então uma tecnologia a ser usada em todos os processadores baseados na arquitetura Nehalem para eliminar o barramento frontal (FSB) conectando a UCP diretamente à memória e ao “southbridge” (onde se originam os barramentos de E/S) e que, em suas configurações mais complexas, pode usar vias independentes para conectar um ou mais processadores (e seus controladores de memória, que passam a integrar cada núcleo) a uma ou mais “southbridges” (entendendo-se aí por “southbridge” todo o conjunto de circuitos controladores das comunicações de E/S, ou seja, aquilo que em inglês é referido como “I/O Hub”) além de interligar os processadores – ou núcleos de um mesmo processador – de forma independente, fazendo com que qualquer um desses componentes possa se comunicar com qualquer um dos demais sem a necessidade de atravessar qualquer barramento comum. Ou seja: acabou-se o “gargalo” do FSB. Bem, para quem prometeu não apelar para detalhes técnicos, já fui longe demais. Porém, seja como for, se tudo o que foi dito acima lhe pareceu meio confuso, tenha em mente apenas o que é mais importante: a partir da arquitetura Nehalem e semelhantemente com o que a AMD já faz há algum tempo, a Intel adotou uma tecnologia própria, a QPI, para eliminar o barramento frontal, evitando o gargalo por ele formado e aumentando significativamente a rapidez do intercâmbio de dados entre os diversos núcleos de um mesmo processador e entre estes núcleos e a memória principal. Um passo de extrema importância em sistemas multiprocessados. Mas esta não foi a única grande inovação agregada à arquitetura Nehalem. Além dela, há a inclusão de um processador gráfico no mesmo encapsulamento da UCP (embora fora dos circuitos internos do processador), o aperfeiçoamento da tecnologia de virtualização (que permite a um único sistema funcionar como se fossem diversos sistemas independentes) e a volta da tecnologia denominada Hyperthreading (capacidade das duas linhas de montagem de um mesmo núcleo de funcionarem de forma semi-independente, simulando um sistema de núcleo duplo, introduzida com a arquitetura Netburst, abandonada na Core e “ressuscitada” na Nehalem). Mas o que – juntamente com a QPI – realmente faz da Nehalem uma arquitetura um passo adiante de seu tempo é a inclusão da tecnologia Turbo Boost, um notável aperfeiçoamento voltado para a otimização do uso de energia e dos recursos de um sistema multinuclear. Um recurso tão interessante que merece um pequeno comentário. Processadores modernos, especialmente os multinucleares, já “sabem” economizar energia de uma forma “inteligente” reduzindo a frequência de operação quando as exigências computacionais diminuem. Assim, se você está, por exemplo, digitando um texto em um editor simples, o(s) núcleo(s) de seu processador passam a funcionar cada vez mais devagar para dissipar apenas a potência solicitada pelas modestas exigências da tarefa leve e gastar menos energia (o que, em sistemas móveis, pode ser traduzido por “aumentar a duração da carga da bateria”, que é o que realmente interessa). Porém, se para enriquecer seu texto você precisa recorrer a números resultantes de complexos cálculos efetuados por uma poderosa planilha eletrônica, quando você executa a nova tarefa o(s) núcleo(s) aceleram, podendo chegar até sua frequência máxima nominal para dar conta das novas – e superiores – exigências de processamento. Este é um recurso relativamente simples e já vem sendo adotado há algum tempo pelos processadores de primeira linha e, nos de mais de um núcleo, pode mesmo ser estendido até o ponto de desativar inteiramente um (ou mais) núcleo(s) quando seu concurso não é necessário, retomando posteriormente sua operação quando forem solicitados. Ora, mas quando se reduz a frequência de operação de um ou mais núcleos porque sua ação não é necessária para cumprir a tarefa que está sendo realizada, não somente se reduz o consumo de energia como também se reduz proporcionalmente a dissipação de potência (portanto, de calor). Ou seja: o(s) núcleo(s) que permanecem em funcionamento o fazem com alguma “folga” no que toca à dissipação de calor mesmo que eventualmente estejam operando em sua frequência máxima. Então, por que não aproveitar esta folga e acelerar estes núcleos mesmo acima de sua frequência máxima nominal? Como há um ou mais núcleos inativados (ou operando em baixa frequência) no mesmo encapsulamento, o sistema de dissipação de calor deverá dar conta do recado. Seria algo como uma espécie de “overclocking oficial”, controlado, dentro dos limites aceitáveis do dispositivo. Pois esta é a idéia da < http://www.intel.com/technology/turboboost/ > tecnologia Intel Turbo Boost. Ela é acionada toda a vez que o sistema operacional solicita o máximo desempenho do processador. Quando isto ocorre, o circuito de controle da Turbo Boost verifica: o número de núcleos ativos naquele momento; o consumo estimado de corrente elétrica; a dissipação estimada de potência; e a temperatura do processador. Com base nestes dados, calcula a “folga” disponível e aumenta, dinamicamente, a frequência de operação do(s) núcleo(s) ativo(s) até atingir o limite aceitável. Este aumento é feito em passos (“steps”) de 133 MHz. Quando, por força da atividade do sistema, a temperatura atinge o limite aceitável pelo dispositivo e ameaça ultrapassá-lo, a frequência é reduzida de 133MHz em 133MHz até que o processador volte a operar na faixa segura. Aí está uma coisa simples, mas eficiente.
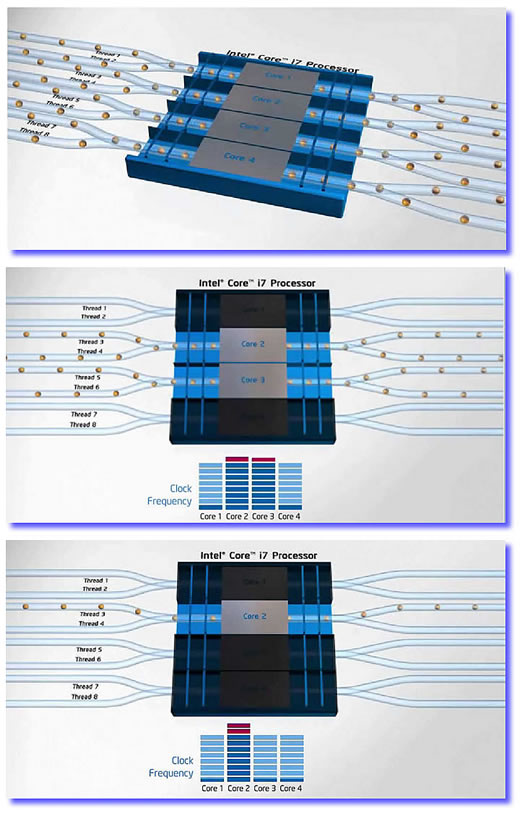
No sítio da empresa você pode encontrar < http://www.intel.com/technology/product/demos/turboboost/demo.htm?iid=tech_tb+demo > um filmete da Intel (infelizmente, narrado apenas em inglês) demonstrando a tecnologia Turbo Boost. A Figura 2 exibe imagens capturadas deste filme (o que explica sua má qualidade, pela qual me desculpo). No alto, o esquema de um processador com quatro núcleos operando com a demanda equilibrada entre eles. O esquema exibido no centro exibe uma situação na qual dois dos núcleos foram desativados por desnecessários à tarefa que está sendo cumprida, que exige apenas o concurso dos dois núcleos restantes. Que, como se pode ver no gráfico de barras no pé da imagem, tiveram sua frequência de operação incrementada para fazer face ao aumento da demanda sobre eles. Finalmente, na parte inferior, aparece um gráfico que espelha uma situação – ao menos por enquanto – relativamente comum: um processador tetranuclear executando um aplicativo antigo, concebido para máquinas de um único núcleo e não recompilado para tirar proveito de núcleos múltiplos. Nesta situação apenas um núcleo suporta toda a demanda do aplicativo e os circuitos de controle do Turbo Boost agem no sentido de desativar todos os três núcleos remanescentes, aumentando em dois passos (“steps”) a frequência do único núcleo mantido em operação (veja gráfico de barras no pé da imagem). Uma beleza de tecnologia, pois não? Pois muito bem: aí está a arquitetura Nehalem. E quais são os processadores que a adotam?
Bem, por enquanto, poucos. O primeiro deles foi o Intel Core i7, já no mercado desde dezembro de 2008. No momento suas características são as seguintes: gravado em uma camada de silício com espessura de 45 nm e baseado na revisão Bloomfield da arquitetura Nehalem tem quatro núcleos, encaixa em um soquete LGA de 1366 contatos, roda em frequências que vão de 2,6 GHz (modelo Core i7 920) a 3,33 GHz (modelo Core i7 Extreme), dissipa 130 W, aceita memórias DDR3 1600 e ostenta um cache de 8 MB (estranhou a expressão “no momento” lá no início da frase? Já explico). No momento (agosto de 2009), além do i7 e aderindo à arquitetura Nehalem, no mercado há apenas a série 5500 do Xeon, para o mercado corporativo, e baseada na subarquitetura (ou “revisão”) Gaineston. Mas brevemente haverá mais. Espera-se ainda para este ano o lançamento dos processadores Core i5 e Core i7 que, na época do lançamento (sim, esta restrição também será explicada), serão baseados nas revisões Lynnfield e Clarksfield e, mais tarde, do Core i3, baseado na revisão Arrandale. Pois é isto. Agora, antes da coluna final que encerrará a série, só falta explicar porque a Nehalem já apresenta tantas revisões logo após o lançamento (já que, normalmente, as revisões, como o nome indica, se sucedem ao longo da vida útil da arquitetura na medida que novas funções são agregadas) e o uso das expressões “no momento” e “na época do lançamento” sempre que me referi às designações i3, i5 e i7. A proliferação de revisões tão cedo deve-se a uma característica singular da arquitetura Nehalem: ela é aquilo que os especialistas classificam como “escalável”, ou seja, pode ter elementos funcionais suprimidos ou agregados dependendo da versão. Por exemplo: alguns parágrafos acima eu mencionei que a arquitetura Nehalem inclui um processador gráfico no mesmo encapsulamento do chip. O que é verdade. Mas nenhum dos processadores Nehalem lançados até o momento dispõe deste processador auxiliar. O que não impede que ele venha a ser incluído em futuras revisões. Assim, as diversas revisões atuais diferem justamente por incluir – ou não – certas funcionalidades. Já quanto ao “no momento”, a coisa fica mais complicada de explicar. Porque, de acordo com a nova estrutura de marca adotada pela Intel, o que hoje é i7 pode não ser amanhã. E vice-versa. Mas isso só ficará claro para quem se der ao trabalho de ler a próxima coluna. Até lá. B. Piropo |