< Coluna em Fórum PCs >

27/03/2006
< IDF Spring 2006: Smart Cache >
|
< Coluna em Fórum PCs >
|
|
|
|
27/03/2006
|
< IDF Spring 2006: Smart Cache > |
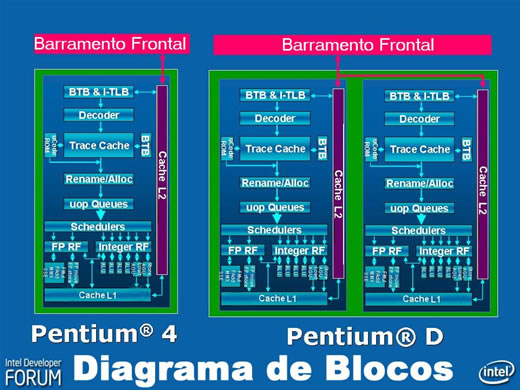
Na coluna "IDF Spring 2006: Microarquitetura Intel Core", discutimos algumas das características da nova arquitetura da futura geração dos processadores da Intel. Nela, mencionamos a dificuldade que teríamos para abordar alguns dos aperfeiçoamentos implementados pela Intel já que esta abordagem dependeria do domínio de conhecimentos técnicos que vão muito além do escopo desta coluna. Mas prometi voltar ao assunto e tentar discutir com um nível de detalhes razoável pelo menos um destes aperfeiçoamentos: o compartilhamento do Cache L2 entre os núcleos dos processadores de núcleos múltiplos, que a Intel denominou “smart cache”. Pois mãos à obra. Mas antes, vamos rever alguns conceitos básicos sobre cache dos quais precisaremos para destrinchar o “smart cache”. Conceito de cache Chama-se “cache” a um trecho de memória de acesso rápido, que se interpõe entre uma memória de acesso mais lento e o sistema que solicita dados desta memória, onde são armazenadas cópias de trechos da memória mais lenta com o objetivo de acelerar o acesso. Quando é solicitado acesso a uma determinada posição da memória mais lenta, o sistema verifica se há uma cópia desta posição armazenada no cache e, caso positivo, a operação é feita diretamente no cache, mais rapidamente devido a seu menor tempo de acesso. “Cache” é um termo do inglês que deriva do francês “cacher”, “esconder” em português. Na prática, para os demais componentes do sistema tudo se passa como se não houvesse cache, já que nenhum deles, exceto o subsistema que controla o acesso à memória, toma conhecimento de sua existência: os dados nele armazenados são fornecidos como se proviessem diretamente do local de armazenamento original, apenas mais rapidamente. É essa a razão do nome, já que as coisas se passam como se os dados estivessem “escondidos” no cache. Como conseqüência da existência de diversos tipos de meios de armazenamento de dados com diferentes tempos de acesso, há diversos tipos de cache. Por exemplo: os discos rígidos modernos incluem na própria placa controladora um conjunto de módulos de memória de tipo semelhante ao usado na memória principal da placa-mãe (ou memória RAM) que constituem o “cache de disco”. Como o acesso ao disco é notoriamente mais lento que o acesso à memória RAM (dezenas de vezes mais lento), a própria controladora do disco copia nestes módulos de memória um conjunto de setores do disco. Caso o sistema solicite a leitura de um destes setores, ele é lido diretamente no cache de disco, acelerando significativamente o acesso aos dados. Apesar de apenas alguns dos setores do disco rígido serem copiados no cache de disco, há uma grande probabilidade de que as próximas solicitações de leitura sejam feitas a estes setores. Isto porque a controladora de disco usa um algoritmo bastante sofisticado para “prever” onde serão feitos os próximos acessos com base nas solicitações mais recentes. Há alguns anos, quando se usavam os lentos módulos de memória do tipo DRAM (RAM dinâmica) para implementar a memória principal, era prática comum inserir entre esta MP e a CPU o chamado “cache externo”, constituído de um conjunto de módulos de memória SRAM (RAM estática), de acesso mais rápido que a DRAM, para armazenar cópias de trechos da MP. Tratava-se de um “cache externo de memória” (compare com o anterior, um “cache de disco”), que caiu em desuso quando se disseminou o uso das memórias SDRAM (RAM dinâmica síncrona), muito mais rápidas. Mas a maioria das placas-mãe de sistemas equipados com os processadores “ 386” e “ 486”, cuja memória principal era constituída de módulos tipo DRAM, ostentava um módulo de cache externo. Os sistemas modernos não precisam de cache externo, particularmente depois do advento das memórias SDRAM do tipo DDR (Double Data Rate, ou taxa dupla de dados), de acesso extremamente rápido. Mas mesmo estas memórias são demasiadamente lentas para permitirem acessos com as freqüências de operação da ordem dos GigaHertz em que funcionam os microprocessadores (ou UCPs) modernos. Por isso, a partir do lançamento do i486 há quase vinte anos, toda UCP usa o chamado “cache interno”, uma memória cache situada no interior da própria UCP que guarda cópias de trechos da MP. Caches em múltiplos níveis A teoria da arquitetura e das estratégias de acesso a caches, que leva em conta os algoritmos de acesso, tamanhos dos caches, rapidez de acesso e latência (que, para simplificar, pode ser considerada como o tempo que o sistema leva “procurando” o dado no cache antes de efetuar o acesso propriamente dito) é bastante complexa e não cabe discuti-la aqui. Mas para entendermos o compartilhamento de caches, assunto desta coluna, é preciso abordar ainda que superficialmente o conceito do cache em múltiplos níveis (“multi-level cache”). A idéia se baseia em um raciocínio simples. Senão, vejamos: quanto maior a capacidade do cache, maior a probabilidade de encontrar nele uma cópia do dado que se procura. Portanto, sob este ponto de vista, um cache grande é melhor que um pequeno porque é maior a probabilidade de que uma cópia do dado esteja nele. Por outro lado, quanto maior o cache, maior a latência, pois mais tempo se leva para encontrar alguma coisa que nele esteja armazenada (não entendeu o porquê? Então procure um livro em uma pilha de dez livros e depois faça o mesmo em uma estante com centenas deles e entenderá). Logo, sob este ponto de vista um cache pequeno é melhor do que um grande porque a latência é menor. Então, há que haver uma solução de compromisso entre probabilidade de encontrar o dado e latência. Infelizmente, tanto a probabilidade de encontrar o dado quanto a latência crescem com o aumento da capacidade. A solução foi hierarquizar o cache. Criou-se então dois níveis de cache, ambos no interior da UCP, o primeiro (de mais alto nível, nível 1 ou L1) um cache pequeno, rapidíssimo, latência curta devido ao menor tamanho, bem junto ao âmago da UCP e o segundo (de nível 2, ou L2), entre o primeiro e o mundo exterior, um cache bem maior, portanto aumentando a probabilidade de encontrar nele uma cópia do dado desejado, porém de maior latência (há processadores, como o Itanium, que usam três níveis de cache no interior da UCP, L1, L2 e L3). Quando a UCP necessita do acesso a uma posição de memória principal, primeiro verifica se há uma cópia desta posição armazenada no cache L1 (o que é feito muito rapidamente devido à baixa latência deste cache). Se houver o acesso é imediato. Se não, verifica se por acaso há uma cópia no cache L2. Se encontrar (e a probabilidade é bem maior devido ao maior tamanho do cache L2), o dado será fornecido não tão rapidamente, mas com rapidez suficiente, já que o dado foi encontrado no L2, ainda no interior da UCP. E somente se também aí não for encontrada cópia, o acesso (neste caso já bem mais lento) é feito diretamente à posição da memória principal. Em resumo: se houver cópia em L1, a pequena latência faz com que o acesso seja quase imediato. Mas, se não houver, ainda há uma probabilidade razoável de encontrar uma cópia em L2, cuja latência é maior, mas cujo acesso ainda é significativamente mais rápido que à MP. Há duas estratégias para lidar com caches internos de múltiplos níveis. A AMD usa a implementação “exclusiva”, em que os dados que estão em L1 são diferentes daqueles que estão em L2 (ou seja, são cópias de diferentes posições da MP). Já a Intel usa a implementação “inclusiva”, em que os dados que estão no cache L1 são um subconjunto daqueles que estão em L2, ou seja, L1 é uma cópia de trechos de L2. Em princípio isto é o que precisamos saber para entender as vantagens do “smart cache”, o cache L2 compartilhado da nova arquitetura Intel Core. Mas se você quiser mais detalhes sobre o funcionamento do cache interno e suas diferentes arquiteturas, recomendo uma visita ao tópico (em inglês) “CPU cache” da enciclopédia livre Wikipedia em < http://en.wikipedia.org/wiki/CPU_cache >. Cache compartilhado Para entendermos o que é um cache L2 compartilhado precisamos antes conhecer a estrutura interna de um microprocessador de cache L2 não compartilhado. Veja, na Figura 1 (adaptada do material de divulgação da Intel distribuído no IDF Spring 2006), os diagramas de blocos que mostram a organização interna dos microprocessadores Pentium 4 (núcleo simples) e Pentium D (núcleo duplo).
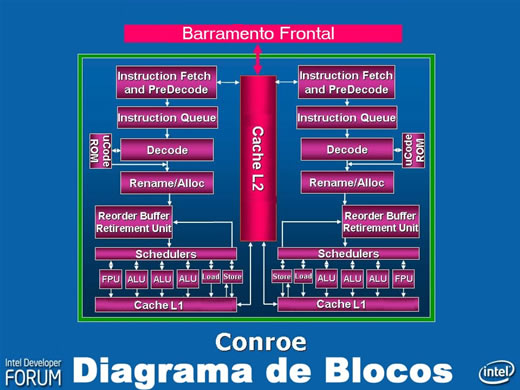
O Pentium 4 é um microprocessador de núcleo único. Repare, no diagrama à esquerda da Figura 1, que seu barramento frontal está ligado diretamente ao Cache L2, através do qual se dá toda a comunicação com o mundo exterior (que, para a CPU, consiste da MP e dos dispositivos de Entrada e Saída, ou E/S). Todos os componentes internos estão interligados e se comunicam com o Cache L1 através da UCP. O cache L1, por sua vez, liga-se diretamente ao Cache L2 (veja na base do diagrama). Desta forma os acessos às posições da MP são feitos sempre através do cache L1, do cache L2 e MP, necessariamente nesta ordem. Se o dado existir em um dos caches, será lido dele. Se não, da memória. Agora examine, no lado direito da Figura 1, o diagrama de blocos do Pentium D, o sucessor de núcleo duplo do Pentium 4. Note que ele nada mais é que dois diagramas idênticos, postos lado a lado, cada um deles igual ao diagrama de blocos do Pentium 4. Ou seja: a arquitetura do processador de núcleo duplo Pentium D nada mais fez que duplicar, lado a lado, a mesma arquitetura do Pentium 4. Um Pentium D funciona exatamente como dois Pentium 4 colaterais, totalmente independentes tanto no que diz respeito ao processamento quanto ao que diz respeito aos caches L1 e L2. Cada núcleo tem seu cache L1 e seu cache L2 e nenhum dos núcleos tem acesso aos caches do outro. Veja agora na Figura 2, também adaptada do material de divulgação da Intel fornecido no IDF Spring 2006, o diagrama de blocos do sucessor do Pentium D, ainda conhecido apenas pelo codinome “Conroe”, um processador de núcleo duplo fabricado com tecnologia de camada de silício de 45 nm a ser lançado ainda este ano com a nova arquitetura Intel Core que discutimos a coluna anterior.
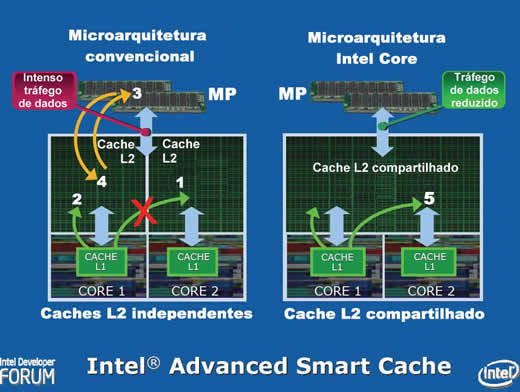
Deixemos de lado as alterações nos componentes de entrada e alguns componentes internos, impostas por novas características da arquitetura Intel Core, e fixemos nossa atenção apenas nos caches L1 e L2. Note que embora cada unidade de processamento (núcleo) continue inteiramente independente no que diz respeito ao processamento e disponha de seu próprio cache L1 (há um para cada núcleo), o cache L2 agora é mostrado como um elemento único, comum aos dois núcleos. Ou seja: é um cache compartilhado, ao qual ambos os núcleos têm acesso. É esse compartilhamento que nos interessa discutir hoje. O “Intel Advanced Smart Cache O “Intel Advanced Smart Cache” é a implementação de cache L2 compartilhado em processadores de núcleos múltiplos adotada pela nova arquitetura Intel Core. Sua adoção, segundo a empresa, “melhora o desempenho e a eficiência aumentando a probabilidade de que cada núcleo de um processador de núcleo duplo possa ter acesso aos dados de um subsistema de cache de alto desempenho e mais eficiente”. O que não explica muito, naturalmente. Então vamos destrinchar. Veja, do lado esquerdo da Figura 3 (mesma fonte das demais), o que acontece quando ambos os núcleos de um único processador que usa caches L2 independentes (não compartilhados) precisam ter acesso a um dado que, por acaso, está armazenado no cache L2 de um dos núcleos. No caso, o núcleo da esquerda (núcleo 1, ou “core 1”) solicita acesso a uma posição da memória principal cuja cópia está armazenada no cache L2 do núcleo 2. Se os caches fossem compartilhados, ele simplesmente teria acesso ao dado como mostra a seta 1. Mas como isso não é possível por serem os caches L2 independentes (ou seja, o núcleo 1 só tem acesso a seu cache, apontado pela seta 2), o acesso precisará ser feito diretamente na memória principal, como mostram as setas 3 e 4. O que aumenta o tráfego no barramento frontal e prejudica significativamente o desempenho, já que acessos à MP são bastante mais lentos que acessos ao cache L2.
Veja agora o que ocorrerá nos processadores que adotam a microarquitetura Intel Core, mostrada esquematicamente no lado direito da Figura 3. Devido, provavelmente, a um acesso anterior realizado pelo núcleo 2, há uma cópia da posição de memória à que o núcleo 1 deseja ter acesso no cache L2 do núcleo 2. Quando o núcleo 1 solicitar acesso a esta posição, o controlador do cache “perceberá” que a cópia está disponível do “outro lado” do cache compartilhado e imediatamente concederá o acesso, mostrado pela seta 5. Isto reduz significativamente o tráfego através do barramento de sistema. Mas este é apenas um aspecto do compartilhamento do cache L2, ou seja, permitir que o acesso a dados previamente armazenados por um dos núcleos no “seu” trecho de cache L2 seja feito pelo outro núcleo. Há um segundo aspecto tão ou mais importante: o gerenciamento dinâmico do cache L2.
O gerenciamento dinâmico do “Advanced Smart Cache” permite que a capacidade do cache L2 seja distribuída dinamicamente, fornecendo a cada núcleo o acesso à capacidade de cache L2 por ele demandada. Trocando em miúdos: se um dos núcleos está envolvido em uma tarefa que exige grande capacidade de processamento e pouco acesso à memória enquanto o outro está executando uma tarefa que exige acesso mais freqüente à memória, o subsistema de gerenciamento dinâmico de cache fornecerá a este último maior capacidade de cache, “roubando” do cache L2 originalmente destinado ao outro. Isto aumenta muito a probabilidade de acertos no cache (ou seja, de encontrar no cache uma cópia da posição de memória desejada). Em casos extremos, quando um dos núcleos estiver ocioso (por exemplo: aguardando uma entrada de dados por parte do usuário) será fornecido ao outro acesso a 100% da capacidade do cache L2 compartilhado. Nas palavras de Justin Rattner, Senior Fellow Chief Technology Officer da Intel, “Nós não estamos particionando o cache de nenhuma maneira. Ele não é privativo de um núcleo individual. A totalidade do cache L2 se tornará compartilhada entre ambos os núcleos”. Como o “ Advanced Smart Cache” é parte integrante da nova arquitetura Intel Core, será adotado por todos os seus membros: Conroe para micros de mesa, Merom para portáteis e o Woodcrest para servidores.
Em resumo: a nova tecnologia de cache adotada pela Intel em seus processadores de núcleo múltiplo, denominada “Smart Cache”, tem por característica o fato de permitir que o cache interno de segundo nível (cache L2) seja compartilhado por ambos os núcleos. Esta característica traz duas conseqüências, ambas revolucionárias. A primeira faz com que, caso um dos núcleos tenha feito acesso recente a uma dada posição de memória principal e, por conseguinte, tenha armazenado uma cópia dela no “seu” espaço de cache L2, se porventura o outro núcleo vier a necessitar de um acesso a esta mesma posição de memória, poderá fazê-lo diretamente na cópia depositada no cache L2 do primeiro, já que todo o cache é compartilhado. Isto pode reduzir significativamente o tráfego no do barramento de sistema, através do qual são feitos acessos à MP. A segunda característica é ainda mais revolucionária que a primeira. Ela se constitui no gerenciamento dinâmico do cache L2, permitindo que, nas ocasiões em que um dos núcleos está ocioso ou fazendo pouco uso de “seu” cache L2, parte (ou até mesmo a totalidade) deste cache seja alocado ao segundo núcleo, aumentando significativamente a probabilidade de que ele encontre uma cópia dos dados no cache, o que aumenta de forma significativa o desempenho do sistema. Este, juntamente com os demais aperfeiçoamentos introduzidos na arquitetura Intel Core, poderá fazer com que a nova geração de processadores da Intel se firme na liderança tecnológica do setor, liderança esta que vinha sendo seriamente ameaçada pela concorrente AMD. B. Piropo |