< Coluna em Fórum PCs >

17/03/2008
< A nova arquitetura Intel: I - Nehalem >
|
< Coluna em Fórum PCs >
|
|
|
|
17/03/2008
|
< A nova arquitetura Intel: I - Nehalem > |
Dentro de alguns dias será realizada na China mais uma edição do Intel Developer’s Forum, um evento promovido regularmente pela Intel para apresentar novos produtos a seus clientes, desenvolvedores e membros da imprensa internacional e discutir seus planos para os próximos anos. E, como de costume, a empresa convocou alguns jornalistas interessados nos aspectos técnicos de seus produtos para participar de uma “apresentação telefônica” (“conference call”) preliminar ao evento. O objetivo desta coluna é levar aos leitores algumas das novidades mencionadas pela Intel durante esta apresentação, mas eu não consigo escrever uma coluna baseado em minha participação em uma “apresentação telefônica” sem um comentário sobre esta forma de fazer apresentações. A “apresentação telefônica” (“conference call”) é uma extensão em tempo real e escala planetária de uma apresentação pública realizada em um determinado local. No caso, o local foi a cidade de San Francisco, na Califórnia, EUA. Os apresentadores foram membros da equipe técnica e direção da Intel, notadamente Pat Gelsinger, Vice-Presidente e Gerente Geral do Digital Enterprise Group da empresa. E a platéia era formada, além de alguns jornalistas da imprensa especializada norte americana que participaram de corpo presente, por um punhado de pessoas espalhadas pelos cinco continentes, que receberam algum material para se inteirar antecipadamente dos aspectos técnicos mais relevantes do que seria apresentado, o jogo de “slides” mostrados durante apresentação e um número de telefone para o qual deveriam ligar na data e hora marcadas para a palestra (a saber, dia 17 de março de 2008, 14 h, horário de Brasília). Isto feito, para participar bastava ouvir atentamente o que estava sendo apresentado a alguns milhares de quilômetros, acompanhando os “slides” na tela de seu próprio computador e, se pairasse alguma dúvida sobre o tema, dirigir por telefone uma pergunta ao mediador, que a proporia ao apresentador que, por sua vez, a responderia imediatamente. Pode ser efeito da idade, sei lá. Velhos, como vocês sabem, se espantam com tudo o que é moderno. Porém, por mais que por dever de ofício eu tenha que me manter absolutamente em dia com os últimos avanços tecnológicos, não consigo deixar de me maravilhar com este tipo de coisa. Ter acesso direto e imediato a quem pode dirimir dúvidas sobre aspectos técnicos de uma tecnologia que ainda está em desenvolvimento é realmente uma coisa notável e seu valor para quem pretende se manter atualizado com o mundo tecnológico é inestimável. Mas deixemos de conversa fiada e vamos ao que interessa. Porque dentre os pontos abordados na palestra de Gelsinger, indiscutivelmente o mais importante foi o tópico sobre a família Nehalem. Nehalem é o nome de código (não comercial) da nova microarquitetura dos processadores Intel. Os primeiros modelos que a adotarão deverão chegar ao mercado no quarto trimestre deste ano. Atualmente o topo da linha Intel de processadores se baseia na família “Penryn”, que deu origem aos processadores “Core”, já na segunda geração (“Core 2”). São processadores fabricados a partir de 2007 que utilizam a tecnologia de fabricação de camada de silício de 45nm e cuja filosofia de projeto privilegiou o alto desempenho com uso eficiente de energia. Agora, sem abandonar estes princípios básicos, a Intel dá um passo a frente e lança a microarquitetura Nehalem, na qual a palavra chave é “escalabilidade”. Mas, afinal, o que vem a ser exatamente “escalabilidade”? E o que se pode esperar de uma família de microprocessadores cuja filosofia se baseia nela? Escalabilidade é um neologismo que nem todos os dicionários de português registram. É derivado do termo inglês “scalability” cujo significado nas áreas de telecomunicações e engenharia de software, segundo a Wikipedia, é: “uma característica desejável em todo o sistema, em uma rede ou em um processo, que indica sua habilidade de manipular uma porção crescente de trabalho de forma uniforme, ou estar preparado para o crescimento do mesmo”. Ou ainda, segundo o Babylon Inglês-Português, a “capacidade de ajustar configuração e tamanho para preencher novas condições; possibilidade de alterar a escala de uma aplicação”. Em suma: por serem dotados desta qualidade desde a concepção, os membros da família Nehalem serão capazes de se ajustar às necessidades e condições deles exigidas. O que não seria muito extraordinário se a Intel não afirmasse que esta escalabilidade se manifestará não apenas durante a operação (“runtime”) como também durante o projeto. A escalabilidade durante a operação já existe atualmente e é conseguida através de aperfeiçoamentos e funções introduzidas nos microprocessadores que permitem que eles ajustem dinamicamente o desempenho (e, portanto, o consumo de energia) em função das necessidades do momento. Na família Nehalem estes ajustes incluirão desde o “desligamento” de núcleos inteiros quando seu concurso não for necessário em sistemas multinucleares, até a redução do número de “threads” (um dos diversos “processos” em que a execução de um programa pode ser subdividida), ajuste da capacidade de cache, interface com os demais componentes e regulagem do consumo de potência, tudo isto para otimizar a relação desempenho/consumo de energia. Desta forma, nas ocasiões em que as exigências de processamento forem mínimas, o consumo de energia cairá a níveis muito baixos. Já aquilo que a Intel denomina de “escalabilidade em nível de projeto” consiste na possibilidade de fabricar diferentes versões de processadores, otimizadas conforme as necessidades do mercado específico (servidor, desktop ou notebook). Diferentes versões poderão ter distintos números de núcleos, diferentes capacidades do cache, interconexão e controle de memória, com diferentes capacidades de processamento porém incorporando exatamente a mesma tecnologia, o que permite atender uma larga faixa de preço, desempenho e consumo de energia sempre empregando a tecnologia de ponta. Note-se que esta escalabilidade em nível de projeto só é possível porque a microarquitetura Nehalem foi concebida já com este fim em mente. Mas, para entender como ela será implementada, será necessário conhecermos mais alguns detalhes sobre a microarquitetura propriamente dita e a nova estrutura de interconexão desenvolvida pela Intel para a família Nehalem (“Quick Path”), portanto voltaremos ao assunto adiante. Entrementes, veja na Figura 1 o aspecto da distribuição dos circuitos internos de um processador Nehalem. E não estranhe a inclusão, nele, de um controlador de memória. Logo você entenderá a razão disso (todas as figuras mostradas nesta coluna foram obtidas do material fornecido pela Intel para a apresentação telefônica).
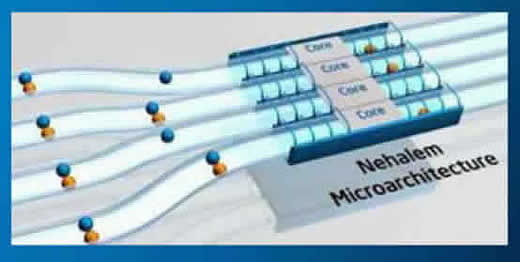
Incidentalmente: talvez alguns leitores achem que esta coluna não será tão didática (ou “explicadinha”) como as que costumo escrever. E, infelizmente, estarão cobertos de razão. Pois acontece que iremos aqui lidar com conceitos avançados de microarquitetura interna de processadores, como “execução fora de ordem” (“out-of-order execution”), “predição de ramo” (“branch prediction”), hierarquia e compartilhamento de cache. E uma coluna “explicadinha” falando sobre isto não seria uma coluna, seria um livro. Por esta razão meu objetivo aqui não será, como de hábito, explicar “como funcionam” os aperfeiçoamentos que a Intel alega haver desenvolvido, mas simplesmente informar aos leitores que eles foram integrados aos processadores. Apesar disto, sempre que possível, lembrarei que leciono a disciplina “Arquitetura e Organização de Computadores” e tentarei simplificar os temas para evitar que a coluna se torne demasiadamente esotérica. Mas há pontos que não admitem simplificações sem notável perda de substância, portanto se acharem que este ou aquele ponto ficou “no ar”, sejam complacentes com este pobre colunista. Há alguns meses (para ser exato, em agosto de 2007) eu expliquei na coluna de mesmo título o que é“O Tic-Toc da Intel”. Trata-se de uma cadência bienal em sua seqüência de desenvolvimento e fabricação de produtos. Nos “anos tic” a Intel desenvolve novas tecnologias e concebe novos produtos. São os anos das novidades. Já nos anos “toc” dedica-se ao aperfeiçoamento destas tecnologias e de seu processo de fabricação Segundo Pat Gelsinger, o ano de 2008, quando virão à luz os primeiros membros da família Nehalem (que incluirá servidores, estações de trabalho e computadores móveis), é um ano “toc”. Logo, a microarquitetura Nehalem é um aperfeiçoamento daquela usada na família Penryn, lançada em 2007. Para ser mais específico, Nehalem mantém a filosofia de alto desempenho com baixo consumo de energia em camada de silício de 45nm da família Penryn e a aperfeiçoa, agregando escalabilidade. Sendo assim a família Nehalem aproveita todas as vantagens da tecnologia “Hi-k metal gate” de 45nm, que usa dielétricos Hi-k (abreviação de “high k”, um tipo de material isolante de óxido de zircônio que minimiza perdas de corrente interna nos transistores; veja mais sobre isto em meu artigo publicado em O Globo em 10/06/2002, “O Terahertz Transistor”, disponível no tópico “Artigos em O Globo” da < http://www.bpiropo.com.br/escritos.htm > seção Escritos do Sítio do Piropo). Uma tecnologia que permite aumentar significativamente a rapidez da comutação de estados do transistor, aumentando assim a freqüência de operação sem aumentar a dissipação de calor. O que, segundo a Intel, estenderá a Lei de Moore até a próxima década. Os aprimoramentos agregados à microarquitetura Nehalem visando o aumento de desempenho voltaram-se principalmente para melhorar a forma pela qual o microprocessador usa os ciclos de operação e consome potência, em vez de simplesmente aumentar a freqüência. Pois o mero aumento da freqüência implicaria aumento proporcional na dissipação de potência e, conseqüentemente, maior consumo de energia, o que contrariaria o princípio básico da nova filosofia Intel: fazer mais usando a mesma potência (ou até menos, quando possível). E, segundo Gelsinger, os esforços da Intel foram tão bem sucedidos que os processadores da família Nehalem conseguirão processar regularmente quatro instruções por ciclo de máquina apelando para um grau de paralelismo sem precedentes na indústria dos microprocessadores (os mais rápidos processadores atuais chegam ao máximo de três instruções por ciclo). Para alcançar este objetivo a Intel recorreu a inovações que incluem gerenciamento dinâmico de número de núcleos ativos, de "threads", dos caches, da interface e do consumo de energia. Durante a apresentação Gelsinger enfatizou que todas as inovações levaram em conta a dissipação de potência. A Intel considera que, hoje, toda plataforma, seja ela um servidor, estação de trabalho ou computador móvel, deve ser otimizada para reduzir o consumo de energia. Por isso sempre avalia a eficiência energética (relação “consumo de potência / desempenho”) de todo aperfeiçoamento introduzido. Como regra, somente são aceitas melhorias que, para cada incremento de três porcento no consumo de energia, agreguem pelo menos um porcento de ganho no desempenho. Por isto as melhorias de desempenho introduzidas na família Nehalem incluem principalmente o aumento da relação “número de instruções / ciclo”. A razão é simples: esta relação contribui não apenas para aumentar o desempenho como também para reduzir o consumo. O aumento do desempenho deriva diretamente do fato de que o processamento é tão mais rápido quanto maior for o número de instruções executadas em um mesmo período. Já a redução do consumo decorre do fato de que, como o gerenciamento de energia dinâmico acompanha as necessidades momentâneas do processamento, quanto mais cedo o processador puder terminar as tarefas, mais cedo voltará a assumir um estado de menor consumo. Para conseguir aumentar o número de instruções por ciclo a Intel recorreu a um conjunto de recursos que incluem os abaixo mencionados. Aumento do parelelismo. Aumentar o “paralelismo” significa aumentar o número de “threads” que podem ser executadas simultaneamente. Isto foi conseguido principalmente aumentando a quantidade de instruções que podem ser executadas antecipadamente ("execução fora de ordem" ou "out-of-order execution"; trata-se de uma tecnologia que permite a alguns processadores pesquisar as instruções situadas mais adiante no fluxo da programação em busca daquelas que não dependem de resultados anteriores e, por isso, podem ser executadas antes do momento previsto para elas, armazenando em “buffers” seus resultados para que sejam usados na ocasião oportuna). Para isto a Intel aumentou o tamanho da "janela" de busca (trecho da memória principal a ser examinado em busca de instruções que podem ser executadas antecipadamente), aperfeiçoou o escalonador de tarefas (“task scheduler”) e aumentou a capacidade dos "buffers" internos de cada núcleo do processador para que não se convertam em um “gargalo" para o desempenho. Adoção de "multithreading" simultânea. Esta tecnologia, anteriormente conhecida por "Hyper-Threading", incorporada pela primeira vez aos processadores da linha Pentium 4 HT (veja detalhes no meu artigo “Hyperthreading”, publicado no jornal Estado de Minas em 14/11/2002 e ainda disponível no tópico “Artigos no Estado de Minas” da < http://www.bpiropo.com.br/escritos.htm > seção Escritos do Sítio do Piropo) permite que um único núcleo atue, em determinadas situações, como se fossem dois, possibilitando assim a execução de duas “threads” independentes por núcleo. Dependendo da aplicação, este aperfeiçoamento pode corresponder a uma melhoria de 20% a 30% no desempenho com um aumento muito pequeno do consumo de energia. Com isto um Nehalem de 4 núcleos pode rodar até 8 "threads" e um sistema multiprocessado com 2 processadores da família Nehalem com quatro núcleos cada pode executar simultaneamente até 16 "threads". Veja, na Figura 2, um diagrama esquemático fornecido pela Intel onde aparecem os dutos (“pipelines”) dos diversos núcleos, alguns deles executando simultaneamente duas instruções de diferentes “threads” (representadas pelas pequenas esferas coloridas).
Aperfeiçoamento dos algoritmos de execução. Segundo a Intel isto se conseguiu através de uma pesquisa rigorosa do desempenho dos processadores da família Penryn em busca de algoritmos que resultassem em atrasos devido à geração de "ciclos mortos" (ciclos de operação em que uma rotina é obrigada a esperar por resultados intermediários). Na microarquitetura Nehalem estes algoritmos foram alterados buscando eliminar ou reduzir o número de tais ciclos. As alterações resultaram em maior sincronização de "threads", redução dos tempos de latência dos acessos à memória através de melhoria nos processos de busca antecipada ("prefetch") e sincronização de acessos ("load-store scheduling") e manejo mais rápido dos "erros de predição de ramo" ("branch misprediction", situações em que, diante de uma escolha condicional o processador decide pelo ramo errado – ver próximo parágrafo). Quando um destes erros ocorre é preciso descartar os resultados intermediários e retomar o processamento em outro ramo, o que implica alguma perda de tempo. Manejando mais rapidamente as operações de descarte, acelera-se o processamento. Melhoria nos algoritmos de "predição de ramo" ("branch-prediction"). Predição de ramo é uma tecnologia que, diante de uma escolha condicional (ou seja, aquela onde é necessário escolher entre dois ou mais “ramos” ou rotinas de programação dependendo do resultado da avaliação de uma condição estabelecida pelo programador) o processador tenta predizer, ou "adivinhar" (em termos escolares: “chutar a resposta”) o ramo a ser executado mesmo antes de conhecer o resultado da avaliação (embora a implementação desta tecnologia seja complexa, a idéia por trás dela é muito simples: se o processador escolheu o ramo certo, ganha-se tempo já que não foi preciso esperar a avaliação da condição; se errou, pouco se perde, já que basta descartar os resultados e, então, retomar a execução no ramo correto, o que teria de ser feito de qualquer modo caso se esperasse pela avaliação da condição). Na microarquitetura Nehalem os algoritmos usados para escolher antecipadamente o ramo foram aperfeiçoados e foi acrescentado ao processador um segundo "branch target buffer" (BTB) que tenta predizer a sub-rotina a ser usada dentro da rotina que está sendo "adivinhada", executando-a e armazenando seus resultados em cache. Além disto foi acrescentada a função de renomeamento do "buffer" da pilha de retorno ("Return Stack Buffer" ou RSB), que armazena os ponteiros associados às instruções de chamada e retorno de funções. Com isto o número de "erros de predição de ramo" ("branch misprediction") se reduz significativamente, acelerando o desempenho sem implicar aumento de consumo de energia. Estas foram as principais alterações nos núcleos dos processadores da família Nehalem. Mas não foram as únicas. Dentre as remanescentes, restaram duas de importância bastante significativa: a alteração da hierarquia de cache com o acréscimo de um terceiro nível, e uma mudança radical na estrutura de interconexão com o abandono do barramento frontal (FSB). Mas estes são os assuntos da próxima coluna. B. Piropo |