< Coluna em Fórum PCs >

15/09/2008
< Computação visual III: afinal, o Larrabee >
|
< Coluna em Fórum PCs >
|
|
|
|
15/09/2008
|
< Computação visual III: afinal, o Larrabee > |
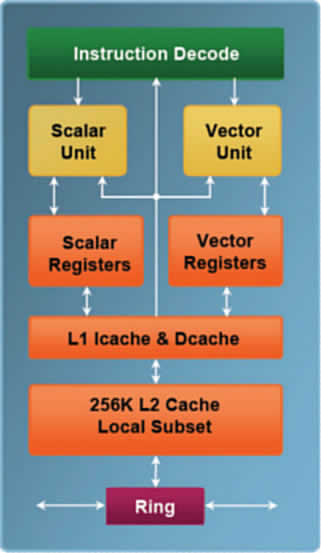
Continuemos nossa jornada em busca do entendimento do que exatamente virá a ser o Larrabee. Sempre lembrando que, como deixei claro na coluna anterior, a jornada atravessa o escorregadio terreno da computação gráfica, área do conhecimento que não domino e sobre a qual, como alguns comentários acrescentados às demais colunas deixam claro, o conhecimento de boa parte dos leitores deste Fórum é significativamente maior que o meu. Mas como os especialistas já se manifestaram e nenhum deles (provavelmente por educação) escarneceu dos meus pitacos sobre o tema, muno-me de coragem suficiente para seguir adiante sempre tendo em mente, porém, que ao sapateiro não convém ir além das sandálias. Como vimos (de forma muito simplificada) há basicamente duas técnicas de renderização de imagens (geração da imagem final a partir de um modelo matemático que fornece as coordenadas dos vértices de suas “primitivas”): rasterização, a mais simples, que consiste basicamente em preencher cada primitiva (polígono elementar no qual a imagem é dividida) com pixels de mesma cor, e traçado de raios (“ray tracing”), mais complexo, que gera a imagem baseada no cálculo do trajeto de cada raio luminoso que incide sobre ela, considerando inclusive seus reflexos nas superfícies representadas na própria imagem. E vimos que este segundo método, embora resulte em imagens muito mais realistas, é pouco usado atualmente devido à brutal capacidade de processamento que exige. Tanto assim que o leitor falconz3, que honrou minha coluna anterior com um comentário em resposta a um comentário postado por marceloxray, afirma literalmente que “o futuro é a utilização de Síntese de Imagem por simulação, como o Ray Tracing”. Pois bem: tanto quanto me foi dado perceber, com a arquitetura Larrabee a Intel tenta antecipar este futuro. Para começar, tentarei transmitir para vocês a que conclusão cheguei, depois de muito fuçar a Internet, sobre a razão da aparentemente paradoxal dificuldade do Dr. Larry Seiler, responsável pelo projeto Larrabee, em responder se o bicho é uma UCP ou uma UGP. E a razão é simples: Larrabee é uma arquitetura, ou seja, um projeto ainda em fase conceitual que englobará futuramente diversos produtos. Alguns deles serão, realmente, UGPs (Unidades Gráficas de Processamento). Mas a flexibilidade da arquitetura é tão grande, como grande será a capacidade de processamento que ela conferirá aos produtos nela baseados que, além daqueles otimizados para processamento gráfico (que, efetivamente, neste caso serão GPUs), haverá outros membros da família Larrabee destinados a finalidades específicas, não necessariamente ligadas ao processamento gráfico – como os aplicativos científicos que envolvem muitos cálculos. E uma das razões disso é a flexibilidade oferecida pela presença de núcleos funcionalmente idênticos a processadores x86 em paralelo com os “módulos de funções fixas” (que logo veremos quais são). Portanto, tinha lá Mr. Seiler suas razões para dar uma resposta tão escorregadia e difícil de entender: chips baseados na arquitetura Larrabee poderão, sim ser UGPs. Mas também poderão não ser. Então voltamos ao princípio: que diabo serão? Bem, tanto quanto me foi dado entender, todos os produtos Larrabee serão do tipo “many-core”, ou seja, terão dez núcleos ou mais (uma das ilustrações da palestra de Seiler mostra um gráfico no qual o eixo correspondente ao “número de núcleos” vai até 48). Cada núcleo obedecerá ao esquema mostrado na Figura 1 (obtida da palestra de Seiler cujo original foi distribuído aos participantes do IDF).
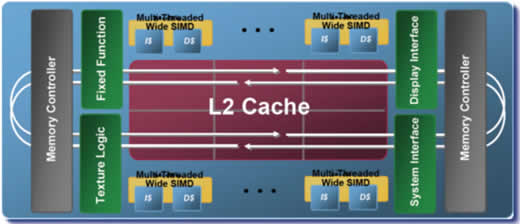
Examinando a Figura 1 com algum critério se percebe que o núcleo de um “chip” Larrabee não é essencialmente diferente do núcleo de qualquer processador x86 da Intel (é por isso que Mr. Seiler afirma tão categoricamente que “o Larrabee não é uma UGP”). Ele terá caches de primeiro nível (L1) independentes para dados e instruções (Dcache e Icache, na figura) conectados diretamente a um cache de segundo nível de 256 KB de rápido acesso (que, como logo veremos, pode ser compartilhado com os demais núcleos), unidades de processamento vetorial e escalar independentes, cada uma com seu próprio conjunto de registradores (os da unidade vetorial de cálculo com decimais terão 512 bits de largura), tudo isto ligado por um lado ao decodificador de seu próprio conjunto de instruções (algumas, mas nem todas, otimizadas para processamento gráfico) e por outro a um misterioso “anel” (“ring”) sobre o qual já falaremos. De fato, outra ilustração da mesma palestra afirma que “cada núcleo Larrabee é um processador Intel completo”, capaz de multitarefa preemptiva (a unidade vetorial é capaz de processar até dezesseis operações de 32 bits por ciclo), uso de memória virtual e caches totalmente coerentes em todos os níveis. A diferença mais substancial é que nenhum dos núcleos será capaz de efetuar o chamado “processamento fora de ordem” (“out-of-order execution”). Um ponto importante: cada núcleo será capaz de processar até quatro “threads” simultâneas e, sendo um processador x86, aceitará qualquer rotina compatível com seu conjunto de instruções e não apenas aquelas dedicadas ao processamento gráfico como as UGPs. E permitirá ao desenvolvedor que tenha acesso ao código fonte das rotinas (ou a algum ambiente de programação integrado específico para o Larrabee), alterá-las à vontade ou programar outras inteiramente diferentes, algo impossível em uma UGP dedicada. Agora que temos idéia de como será cada núcleo do Larrabee, vejamos na Figura 2 como eles se interligam e o que mais o chip oferecerá. E para isso nada melhor que a própria ilustração da Intel apresentada por Larry Seiler. Figura 2: Diagrama de bloco de um “chip” Larrabee
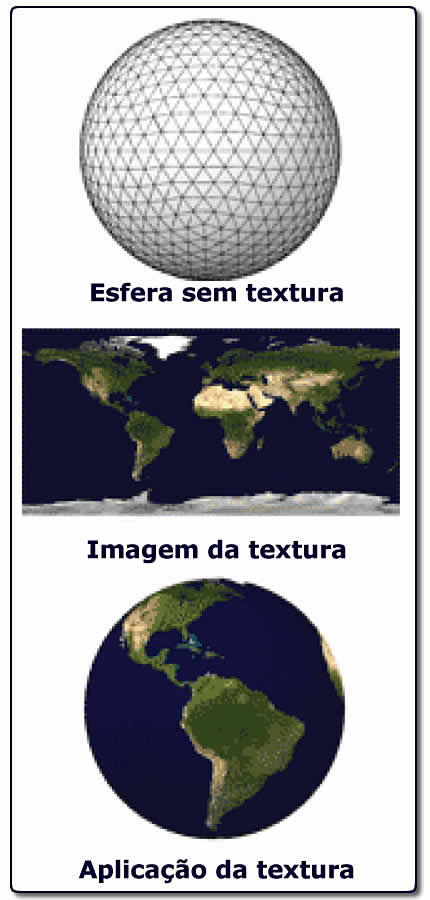
Os núcleos (são mostrados apenas quatro deles) aparecem na parte de cima e na de baixo, com seus dois caches primários (de instruções e dados, I$ e D$). Todos estão ligados a um grande cache de segundo nível (L2 Cache), compartilhado entre eles (como cada núcleo dispõe de um cache L2 de 256 KB, em um Larrabee de, digamos, dez núcleos a capacidade total de cache L2 será de 2,5 GB). Este cache disporá de mecanismos de controle que permitem que um determinado núcleo “trave” trechos de cache para seu uso exclusivo quando estiver executando instruções sobre múltiplos dados (SIMD) impedindo que outros núcleos “sujem” o cache. Mas o que o Larrabee tem mesmo de especial é o que aparece além dos núcleos e do cache: controladores de memória (eliminando barramento frontal e o gargalo que ele representa) e os módulos de funções fixas, tudo isto interconectado por um barramento extremamente rápido, o “ring” (na figura, representado pelas setas brancas). Pois é justamente a presença destes módulos de funções fixas que levou Mr. Seiler a afirmar que “o Larrabee não é uma UCP”. Estes módulos de funções fixas são, justamente, o que o nome indica: módulos de processamento “especializados”, otimizados e dedicados a cumprir uma única função (e é este o ponto de contato mais íntimo entre o Larrabee e as UGPs clássicas, que nada mais são que poderosíssimas unidades de processamento dedicadas exclusivamente às funções gráficas). Na Figura 2, três dos módulos de funções fixas têm suas funções assinaladas (o quarto consta apenas como “Fixed Function”, dando a entender que, dependendo do modelo do “chip” – que, como vimos, pode ou não ser uma UGP – poderá executar qualquer função fixa para a qual for concebido). Um deles é responsável exclusivamente pela lógica das texturas de recobrimento das diversas superfícies que compõem a imagem (“Texture Logic”). Outros dois se dedicam exclusivamente a controlar o intercâmbio de dados com o sistema e com o vídeo propriamente dito (o que permite que as trocas de informações e comandos entre o Larrabee e o sistema não interfiram com a exibição das imagens na tela). Notem que estes módulos se dedicam a funções bastante específicas (a Intel justifica a inclusão da lógica das texturas entre estas funções fixas porque, dadas certas peculiaridades da tarefa, ela pode ser executada de doze a quarenta vezes mais rapidamente por um núcleo dedicado que por processadores genéricos; veja exemplo da aplicação de textura sobre um sólido formado por primitivas na Figura 3).
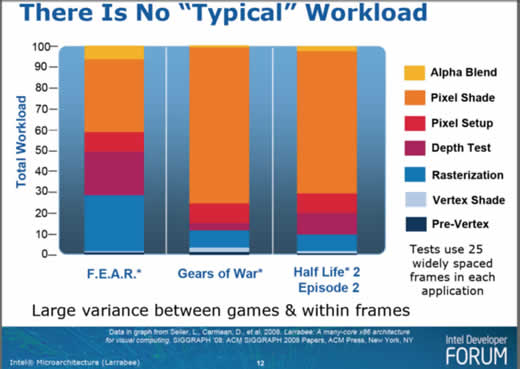
Como foi dito antes, o Larrabee não se destina exclusivamente a processamento gráfico. Mas tem tudo o que é preciso para esta tarefa. O fato de conter múltiplos núcleos, cada um deles funcionando como um microprocessador independente e não “especializado”, permite otimizar o uso do dispositivo, distribuindo tarefas entre os núcleos na medida que são solicitadas. Como, conforme enfatizado na palestra de Seiler, não existe “demanda típica de trabalho” no processamento gráfico (o que é evidenciado na Figura 4, exibida na palestra, que mostra como diferentes aplicativos tridimensionais – no caso, jogos – distribuem de forma totalmente diferente sua solicitação de carga de processamento sobre a UGP), a possibilidade de usar o mesmo núcleo em diferentes momentos para tarefas distintas aumenta brutalmente a capacidade de atendimento de cargas cuja solicitação varia com o contexto. O que traz ainda outra vantagem considerável: como os núcleos não têm limitações quanto ao tipo de função que podem executar, pouco importa para um chip Larrabee se a interface de programação gráfica usada foi a OpenGL ou DirectX: sendo a diferença entre ambas apenas a forma pela qual as funções foram implementadas e podendo os núcleos do Larrabee lidar com diferentes implementações, elas serão aceitas e executadas sem dificuldades.
Agora que sabemos alguma coisa sobre o Larrabee, vamos juntar a estes os (poucos) conhecimentos que temos sobre renderização de imagens. No começo, mas bem no começo mesmo, as imagens eram renderizadas pela própria UCP. O que não era de admirar já que, naqueles dias, o máximo que se podia esperar era o padrão gráfico CGA (Color Graphics Adapter) com suas telas de, no máximo, 320 colunas por 200 linhas e suas vibrantes dezesseis cores (não, milhões não, dezesseis mesmo). A UCP recebia os dados do aplicativo, efetuava os cálculos de transformadas e iluminação, gerava a rede de primitivas, rasterizava a imagem preenchendo as primitivas com pontos de uma das 16 cores disponíveis, processava os pixels e gerava o quadro (“frame”), exibindo-o na tela. Era simples assim. Depois, apareceram as interfaces gráficas e tanto a quantidade de pontos na tela (resolução) quanto o de cores atingiram números inimagináveis. Surgiram então os processadores gráficos dedicados, ou UGPs, especializados, voltados especialmente para a renderização rápida de imagens altamente definidas. E o aumento das exigências da computação visual por imagens cada vez mais realistas fez com que desempenho destes processadores especializados sofressem incremento proporcional. Segundo Seiler, a partir de 2001 este desempenho (medido em FLOPS, ou operações com números fracionários por segundo) tem crescido exponencialmente com taxa de 1,7 vezes ao ano. E o mundo das “placas aceleradoras gráficas” (controladores de vídeo com unidade de processamento gráfico dedicada) primeiro expandiu-se, com grande quantidade de marcas e modelos, depois encolheu e reduziu-se a um número mínimo de participantes não somente pelo notável grau de especialização exigido como também pela crescente complexidade de projeto e custos cada vez maiores. O problema é que a especialização, se bem que acelera o desempenho, tem lá seus problemas. E o maior deles é a perda de flexibilidade. Um circuito “dedicado” faz cada vez melhor e mais depressa seja lá o que foi concebido para fazer, mas faz apenas aquilo. E só quando solicitado. E se tem uma coisa que o Larrabee esbanja, com suas quatro “threads” por núcleo, é flexibilidade. Sem falar no paralelismo: afinal, são mais de dez núcleos cada um capaz de executar quatro “threads” simultâneas. Portanto, se ele não foi “feito por encomenda” para processamento gráfico (a Intel relutaria bastante em afirmar que sim, porém também não afirma peremptoriamente que não), tem todo o jeito de ter sido. Mas ainda assim Mr. Seiler tem razão: o Larrabee não é uma UGP. E, na palestra, citou três razões para justificar esta afirmativa. A primeira é que cada núcleo do Larrabee é um processador Intel completo, capaz de multitarefa preemptiva, acesso à memória virtual e a uma hierarquia de cache coerente. A segunda é que a intercomunicação entre componentes (o “ring”) é um barramento de baixíssima latência e alta taxa de transferência unindo caches de primeiro e segundo níveis e sincronização rápida entre núcleos e caches. A terceira é que, não tendo componentes “dedicados” (com exceção dos poucos módulos de função fixa), a maioria dos gargalos serão eliminados mediante a redistribuição de tarefas entre núcleos, o que resultará em uma funcionalidade mais flexível e equilibrada. Mas o que tem tudo isto a ver com renderização de imagens? Tudo. Lembra da coluna anterior? Da explicação sobre as dificuldades de gerar imagens renderizadas por traçado de raios devido à grande capacidade de processamento que demanda? Pois bem: segundo os especialistas, o cálculo da trajetória de raios luminosos não difusos originados de reflexos nas superfícies representadas nas imagens, especialmente aqueles que são refletidos sucessivamente por diferentes superfícies (“multibounce specular reflections”), assim como o cálculo da trajetória de raios refratados em superfícies transparentes, apresentam enorme demanda de capacidade de processamento. Por outro lado seu alto grau de coerência facilita bastante seu cálculo por sistemas que adotam o processamento paralelo, especialmente de instruções aplicadas simultaneamente a dados múltiplos (processamento SIMD, de “Single Instruction, Multiple Data”). Exatamente como o adotado pelos núcleos múltiplos da arquitetura Larrabee (ver Figura 2). Portanto, até pode ser que o Larrabee não seja uma UGP e nem sequer tenha sido concebido especialmente para processamento gráfico baseado no traçado de raios (“ray tracing”) e que tenha muitas outras aplicações. Mas que parece ter sido feito sob medida para este fim, lá isto parece. E o fato do Larrabee ter sido discutido exclusivamente nas seções técnicas do IDF referentes à computação visual é um bom indicador que logo teremos uma UGP Larrabee. Incidentalmente: em todos os IDFs de que participei, e foram muitos, nunca vi a Intel fazer tanto barulho em torno de um dispositivo que ainda não está “no silício” (ou seja, do qual não existe sequer um protótipo fabricado). O Larrabee foi a exceção que confirma a regra e o fato não deixou de ser mencionado pela própria Intel. Há quem diga que isto se deve a uma estratégia de mercado. Que todo este estardalhaço em torno da CVC (Computação Visual Conectada) é a forma que a Intel encontrou para, digamos, “assustar” a concorrência informando não somente que o tema da computação gráfica não escapa da sua área de interesse como também que está começando a trabalhar nele com afinco. E por “concorrência” entenda-se não apenas a AMD, que desde a aquisição da ATI, há dois anos, vem se dedicando a desenvolver um processador híbrido, incorporando as funções de processamento de dados e de gráficos (programa “Fusion”, anunciado em outubro de 2006; veja as últimas novidades neste < http://arstechnica.com/news.ars/post/20080804-purported-details-leak-on-amds-fusion-cpugpu.html > artigo de Joel Hruska na “ars technica”), como também a NVIDIA, com suas formidáveis placas gráficas de alto desempenho. Eu não sei não, mas pelo que eu vi no IDF, se tudo aquilo é para assustar a concorrência eu, se fosse concorrente, estaria um bocado assustado... B. Piropo |