Na coluna anterior, < http://blogs.forumpcs.com.br/bpiropo/2010/10/04/2883/ >
http://blogs.forumpcs.com.br/bpiropo/2010/10/04/2883/
“Aceleradoras de vídeo: 2D”, vimos como é mais difícil do que parece “desenhar” imagens na tela e como, para que esta tarefa seja cumprida com a necessária rapidez, foram desenvolvidas as “placas aceleradoras de vídeo” que dispõem de um coprocessador especializado na geração de imagens, o UGP, para aliviar a UCP da pesada carga de processamento exigida pela exibição de gráficos de alta resolução.
Mas nos limitamos a discutir os aspectos dos gráficos bidimensionais. E fechamos a coluna informando que, quando se trata de tridimensionalidade, a coisa muda de figura.
E muda mesmo. E não só no sentido figurado.
Mas antes vamos esclarecer o que consideramos “tridimensionalidade”, “gráficos em terceira dimensão” ou “3D”.
Para começar é importante destacar que nosso tema nada tem a ver com a grande novidade do momento no campo das artes visuais: os filmes cinematográficos (e, sim, também placas de vídeo e televisores) que, com o uso de óculos especiais e da exibição de duas imagens superpostas e simultâneas em uma única tela, fazem com que o espectador tenha a percepção de tridimensionalidade e geram imagens que parecem saltar ou se projetar para fora da tela. Definitivamente, não é disso que trataremos nesta coluna (mas se você quer saber como funciona, eu explico: nossa percepção de tridimensionalidade, ou de “profundidade da imagem”, deve-se ao fato de que cada um de nossos olhos capta uma imagem ligeiramente diferente do mundo que nos cerca, imagens cujo “ponto de vista” é deslocado por uma distância igual à que separa nossas pupilas; os nervos óticos transmitem ambas as imagens para o cérebro, que as “monta” e compara, levando em conta as pequenas diferenças e a distância interpupilar, o que faz com que percebamos quais objetos estão perto e quais estão mais afastados; a indústria se aproveitou disso para filmar cenas com duas câmaras cujas lentes estão separadas por uma distância equivalente à separação entre nossas pupilas e efetuar a exibição simultânea destas cenas, cada uma usando a luz polarizada em um ângulo ortogonal à outra; os óculos, por sua vez, têm lentes polarizadas que fazem com que cada olho capte apenas a imagem da câmara correspondente, que é enviada ao cérebro que, por sua vez, monta as imagens e “sente” a profundidade).
Pois bem, não é disto que trataremos. Como também não é do efeito aparente de três dimensões que certas imagens apresentam mesmo quando exibidas em uma tela comum. A isto se chama “perspectiva”, efeito magnificamente ilustrado pela Figura 1 (obtida na Wikipedia) onde se percebe claramente quais degraus se situam mais perto e quais se situam mais longe do observador, além das mudanças da direção dos diferentes lances da escada. Repare como, na figura, todas as linhas paralelas convergem para um único ponto (o “ponto de fuga”) e note a redução das dimensões da altura e largura dos degraus na medida em que se afastam. Assim se consegue uma ideia de profundidade usando apenas duas dimensões. Mas, definitivamente, não é isto que chamaremos aqui de “imagem tridimensional”.
 |
Figura 1: Efeito da perspectiva |
Como também não é tridimensional a imagem do gato mostrada à esquerda da Figura 2, embora os jogos de luz e sombra e sua aparência geral deixem claro quais partes se situam mais próximas e quais se situam mais distantes do observador. Este efeito pode ser obtido decompondo a imagem em polígonos como o busto mostrado na Figura 3 da coluna anterior e o “modelo” de gato mostrado do lado direito da Figura 2 (obtida no < http://www.brogui.com/2009/02/03/desenhos-finalizados-x-wireframes-voce-acredita/ > blog do Broqui, onde podem ser encontrados outros exemplos semelhantes) e preenchendo cada polígono com a cor adequada. O resultado desta decomposição em polígonos, denominado “wireframe” (que, mal traduzindo do inglês, significa “envoltório de arame”, como se o lado de cada polígono fosse constituído por um pedaço de arame que, no conjunto, se entrelaçariam e formariam um modelo tridimensional que se ajustaria ao contorno do objeto) é que dá a ilusão de “três dimensões”.
 |
Figura 2: Imagem de um gato e seu “wireframe” |
Modelos como estes (e aqui não me refiro ao “wireframe”, mas ao modelo matemático, ou seja, o conjunto de equações que permite localizar as coordenadas na tela de cada vértice dos polígonos) também são gerados por placas aceleradoras, porém do tipo bidimensional, ou “2D”. Eles fornecem a impressão de figuras em três dimensões, mas geram um conjunto de pontos coloridos que são armazenados na memória de vídeo e exibidos no monitor um ao lado do outro, linha após linha, ou seja, usam apenas as duas dimensões da tela para “achatá-las” antes de exibi-las.
As complexidades do 3D
Então, afinal, o que faz uma placa aceleradora “3D”?
Bem, a noção de “placa aceleradora 3D” está ligada à percepção do movimento.
Eu entendo que parece estranho (e de fato é), mas a grande dificuldade em criar a ilusão da tridimensionalidade usando uma tela plana como a dos computadores não é a perspectiva nem a proporcionalidade, mas sim duas questões fundamentais, ambas ligadas ao deslocamento de objetos: a ilusão de que as coisas que estão mais próximas “deslizam” sobre as que estão mais afastadas quando elas (ou nosso ponto de vista) se deslocam, e o jogo de luz e sombra que acompanha o deslocamento dos objetos ou dos focos de luz que os iluminam. E nada disto se manifesta em imagens estáticas.
Portanto não é de estranhar que quem deu (e continua dando) o maior impulso para o desenvolvimento de placas aceleradoras 3D foram os jogos e animações gráficas.
Então vamos ver porque tudo isto é tão complicado.
A noção de movimento dos corpos na tela – seja em uma singela animação em duas dimensões, seja em uma elaboradíssima cena de ação de um jogo de última geração – é dada pela rápida sucessão de imagens estáticas.
A mecânica deste efeito é conhecida e não há razão para estendermos sua discussão, mas convém abordar pelo menos as noções básicas.
 |
Figura 3: Ilusão de ótica |
Então, vamos lá. Coloque a Figura 3 no centro de sua tela, aumente o brilho e olhe fixamente para ela, sem piscar nem mover o olhar por pelo menos trinta segundos. Depois, feche os olhos ou olhe para uma tela ou parede bem escura. Você terá uma “ilusão de ótica”.
Se você tiver alguma sorte e uma imaginação fértil, a ilusão lhe fará ver o rosto de Marilyn Monroe. Se a imaginação não for tão fértil, verá simplesmente um rosto. E, na pior das hipóteses, verá uma mancha luminosa no centro de seu campo de visão.
Isto se deve à “persistência retiniana”, um fenômeno visual descoberto pelo cientista belga Joseph Plateau, que consiste no fato de uma imagem permanecer gravada por algum tempo em nossa retina (o tecido sensível à luz que reveste o fundo do interior do globo ocular). No caso da Marilyn, como você olhou fixamente para a imagem por um período considerável, a permanência se estende por alguns segundos. No caso das imagens comuns de nosso dia-a-dia, o tempo de permanência da imagem na retina é de cerca de um décimo de segundo.
Ora, isto quer dizer que se mudarmos rápida, regular e sucessivamente as imagens sobre uma tela (seja as projetadas em uma tela de cinema, seja as geradas na tela de seu monitor), elas se superporão por uma fração de segundo. Nossos olhos captarão uma imagem antes que a anterior tenha se “dissolvido” em nossa retina e assim sucessivamente. E se as imagens que se sucedem mostrarem o mesmo objeto, porém ligeiramente deslocado em relação à posição da imagem anterior, teremos a impressão que ele se move na tela.
O cinema se aproveita disto projetando imagens que se sucedem 24 vezes por segundo. Na tela de seu monitor, devido a problemas como cintilação e outros que não cabe discutir aqui, a sucessão de imagens tem que ser mais rápida, em geral da ordem de sessenta a setenta por segundo.
Pois bem: em um filme que “passa” em seu monitor exibindo, por exemplo, uma bucólica cena no campo, cujas imagens foram captadas por uma câmara de vídeo e simplesmente repetidas uma após a outra na tela, quem se encarrega de criar o efeito de tridimensionalidade é a natureza. É ela que ilumina o cenário e tudo nele presente, criando os efeitos de luz e sombra e superpondo os objetos na ordem correta, fazendo com que os que estão mais perto escondam os que estão mais longe quando se situam sobre a mesma visada e coisas que tais.
Mas em um jogo, por exemplo, ou em qualquer animação criada por um computador, a coisa é diferente. Cada imagem é uma “cena” que tem que ser gerada individualmente antes de ser exibida na tela. E cada efeito tem que ser criado pelo computador. E como se consegue isto?
Primeiro o computador tem que gerar cada objeto da cena (e do cenário) “desenhando” polígonos (quase sempre triângulos) que, juntos, constituem seus “wireframes”, calculando as coordenadas de todos os vértices. Isto gera a forma do objeto.
Em seguida é preciso considerar a “textura” de cada um dos triângulos. Textura é uma qualidade da superfície ligada especificamente ao sentido do tato e da visão. No que diz respeito ao tato (textura física), tem a ver com lisura e rugosidade. No que toca à visão (textura visual), tem a ver com a forma pela qual reflete a luz (brilhante ou opaca, difusa ou focada).
Em artes visuais, como nas animações por computador, há que se simular a textura física com características meramente visuais. Se o efeito desejado for alcançado, será possível distinguir, simplesmente inspecionando o objeto visualmente, se sua superfície é de madeira, vidro, porcelana, metal, couro, pele humana, pelo de animais, penas de aves ou seja lá do que for. E se está seca ou molhada, se é viscosa ou lisa, rígida ou elástica.
Nas telas de computadores a textura é simulada pela repetição de formas e linhas e pode ser mais ou menos realística. Os elementos que constituem a textura são denominados “Texels” (de “Texture Cells” ou “Texture Elements” para manter a analogia com “pixels”). A aparência visual do corpo representado em uma tela tridimensional é obtida aplicando os “texels” sobre os respectivos “pixels” nos polígonos que formam sua estrutura. O exemplo mais simples: considere uma parede em forma de retângulo. Em uma tela tridimensional sua posição é definida pelas quatro coordenadas dos vértices. Mas seu aspecto é dado pelos texels que a recobrem. Mude-os e você verá, por exemplo, uma parede de pedra transformar-se em uma de tijolo ou ser recoberta de hera.
Depois que cada polígono elementar é revestido com sua textura, é preciso calcular a intensidade da iluminação que incide sobre cada um deles em função das coordenadas e da intensidade da fonte de luz (que pode ser mais de uma). Triângulos mais perto da fonte, assim como triângulos situados em um plano perpendicular ao do raio luminoso que parte da fonte, aparecem mais claros.
Para que se obtenha um efeito realístico, a luminosidade (ou seja, a qualidade de “claro” ou “escuro”) de cada triângulo tem que ser calculada individualmente baseada nos dois fatores acima citados, mas não apenas neles. Há também que se levar em conta o fato de que se houver um objeto opaco situado entre o polígono e a fonte, sua iluminação será proveniente da luz refletida pelos demais objetos da cena. E considerar, caso existam objetos “atrás” dele, a projeção de sua sombra sobre estes objetos.
Da mesma forma, se o objeto que se interpõe entre o polígono e a fonte for semitransparente ou translúcido, a redução correspondente na intensidade da luz que o atravessa deve ser considerada. Assim como deve ser considerada, em função da textura do polígono, a quantidade de luz que ele reflete e a direção do raio luminoso refletido, para que esta influência seja levada em conta na iluminação dos demais objetos da cena.
Veja, na Figura 4, como tudo isto é bem ilustrado pelo famoso (bem, ao menos na comunidade da computação gráfica ele é famoso) “Utah Teapot”, ou “bule de Utah”, um modelo clássico de objeto tridimensional criado em 1975 por Martin Newell (veja mais sobre ele na Wikipedia, < http://en.wikipedia.org/wiki/Utah_teapot > onde a imagem foi obtida). Trata-se de um objeto simples, de textura clássica, iluminado simultaneamente por duas fontes luminosas.
 |
Figura 4: O bule de Utah |
Repare nas duas sombras que aparecem no plano inferior, na sua diferença de tonalidade (proporcional à intensidade de cada fonte) e na parte mais escura correspondente à superposição de ambas. Note a textura do bule, levemente enrugada, e como isto gera seu próprio efeito de luz e sombra. Repare nos reflexos das duas fontes sobre o bojo do bule e note como este reflexo se afina e encurva no bico.
Agora pense: o bule não existe. Ele não passa de um modelo matemático que criou o wireframe, calculou os efeitos de luz e sombra, assim como os reflexos e o revestiu com os texels correspondentes à textura desejada (e imagine o que aconteceria se o autor resolvesse substituir esta textura por uma correspondente, por exemplo, a um tecido de veludo opaco). O resultado parece efeito de magia, mas não passa de matemática aplicada.
E isto tudo sem mencionar a “atmosfera”. Por exemplo: pense nos objetos espalhados em uma sala cheia de fumaça. Ou imagine que as imagens reproduzem a visão do piloto de um avião que penetra em uma formação de nuvens cuja densidade muda à medida que ele se desloca dentro delas. Ou em um ambiente aberto, surreal, em que não exista ar, mas uma mistura de gases coloridos mais ou menos transparentes. Ou no reluzir do fogo (e sua influência sobre a iluminação de todos os objetos da cena). Pois tudo isto exerce influência na tonalidade e na reflexão da luz em cada objeto da cena. Pois para gerar uma cena (preste atenção: uma única das muitas cenas que se sucedem na animação) tudo isto tem que ser calculado.
Feitos todos estes cálculos, cada polígono tem sua posição determinada, é revestido com sua textura e recebe a devida quantidade de luz. Chega-se então àquilo que se poderia chamar de “modelo matemático” da cena, ou seja, o resultado de toda esta calculeira. Este modelo é afinal submetido a um processo que, por falta de nome melhor, convencionou-se chamar de “renderização”, que a Wikipedia (em inglês) define como “o processo final de criar a imagem bidimensional real da cena”. Que, ainda segundo a Wikipedia, é análogo a produzir uma foto da cena depois que todos os cálculos foram feitos. Ou seja: todo o processamento é “traduzido” em cores de pixels individuais que são armazenados na memória de vídeo na devida ordem e passam a constituir uma “cena”, ou seja, uma representação bidimensional de um cenário tridimensional.
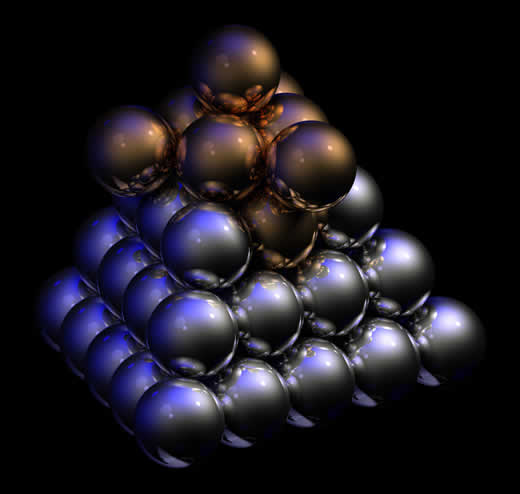
O resultado pode ser assombroso. Examine a Figura 5, uma cena criada por Jawed Karim e igualmente obtida na < http://en.wikipedia.org/wiki/File:Raytraced_image_jawray.jpg > Wikipedia. São apenas três esferas, vistas de cima, no fundo de uma caixa quadrada cujas paredes refletem parte da luz e iluminadas por um único foco luminoso.
 |
Figura 5: esferas |
Repare que a esfera situada próxima ao canto inferior esquerdo é transparente. Veja o canto do fundo da caixa através dela. Note, nela, o reflexo da bola maior. Repare nas sombras sobre o fundo e paredes e na textura das esferas, particularmente na da maior. Note os reflexos da luz nas esferas e nas paredes. Veja como a imagem de cada esfera interage com as das demais, inclusive iluminando-as com seu reflexo. Deu para perceber a complexidade da coisa?
Agora pense: estamos falando de uma animação, onde há movimento. E qualquer movimento – dos objetos representados na cena, da(s) fonte(s) de luz ou do observador, acarreta mudanças substanciais, alterando a cena e, portanto, forçando com que sua representação na memória de vídeo seja recalculada. E toda aquela imensidão de cálculos tem que ser refeita no mesmo ritmo com que as cenas são “trocadas” na tela, ou seja, de 20 a 120 vezes a cada segundo.
Mas, espere um pouco: tudo isto acaba resultando em uma imagem plana, gravada na memória de vídeo e desenhada em uma tela plana, portanto de duas dimensões.
Onde está, afinal, a tão falada tridimensionalidade?
O eixo dos Z
O universo é tridimensional. Na verdade há quem afirme que ele tem muitas mais dimensões, mas vamos ficar aqui com o singelo universo newtoniano e nos restringirmos às boas e velhas largura, altura e comprimento, nossas bem conhecidas três dimensões.
Quando olhamos para uma cena de animação gerada por uma placa aceleradora 3D e exibida na tela de nosso computador nos damos conta apenas da largura e altura, as duas dimensões que aparecem na tela. Se quisermos identificar um determinado pixel nesta tela, podemos fazê-lo especificando duas distâncias: uma, horizontal, da moldura esquerda até ele, outra, vertical, dele até a moldura superior (não reclamem comigo; eu sei que vocês estão acostumados a medir esta segunda distância “de baixo para cima”, até a moldura inferior, mas por razões que não cabem discutir aqui, nas telas de computadores ela é medida “de cima para baixo”). Se nós batizarmos a moldura esquerda de “eixo dos Y” e a superior de “eixo dos X”, poderemos identificar a posição de qualquer pixel na tela fornecendo estas duas distâncias (ou “coordenadas”) X e Y. Como sabemos, todo este conjunto de pixels (na verdade, os números que representam suas cores, o que dá no mesmo) estão armazenados na memória de vídeo.
O problema é que até agora discutimos apenas uma parte da verdade. Porque quando as placas aceleradoras geram imagens em 3D, o conjunto de pixels que representa uma cena ocupa apenas uma parte da memória de vídeo, parte esta denominada “frame buffer” (que, mal traduzida do inglês, significa mais ou menos “armazenamento de um quadro” – ou de uma cena). Mas além do frame buffer, a UGP se serve de mais duas regiões da memória.
Em uma delas são armazenadas as texturas. E não vamos perder muito tempo com ela, já que sua função é simples: como um objeto pode desaparecer de cena e depois retornar, ou “se esconder” por detrás de outro e reaparecer, melhor manter sua textura armazenada para não ter que recriá-la sempre que o objeto tiver que ser renderizado. Vamos então à outra, que é a que nos interessa: o “z-buffer”, ou a região da memória que armazena as coordenadas “Z”.
Mas que coordenadas “Z” são estas que surgiram assim de repente?
Ora, você sabe. Pense um pouco: se a largura e a altura são, respectivamente, representadas pelas coordenadas “X” e “Y”, em um mundo tridimensional a coordenada “Z” só pode representar uma coisa: o comprimento. Ou, melhor dizendo: a dimensão perpendicular à tela. A profundidade. Que, no nosso caso, representa a distância entre o plano da tela e a posição que o ponto teoricamente ocuparia “por detrás” dela.
Então trace uma linha imaginária a partir do canto superior esquerdo de sua tela e se prolonga para trás dela até o infinito, perpendicularmente a seu plano. Esta linha é o “Eixo dos Z”.
Pois bem: o terceiro trecho de memória de vídeo ao qual nos referimos, denominado Z-buffer, armazena a coordenada Z de cada pixel da tela.
Para que serve isto, se as imagens renderizadas (ou seja, as cenas armazenadas no frame buffer) já levam em conta a posição dos objetos aos quais pertencem cada pixel?
Se as imagens permanecessem estáticas, não serviriam para nada. Mas, como sabemos, tridimensionalidade em computação gráfica tem muito a ver com movimento, deslocamento, mudança de posição. E quando passamos de uma cena para a próxima, todo o frame buffer tem que ser refeito.
Ora, para refazer (recalcular) o frame buffer é essencial manter um registro da distância entre cada objeto (ou entre cada pixel pertencente a cada objeto) e o plano da tela. E a razão disto é simples: se o objeto que se move estiver mais distante que o que permaneceu imóvel, como por exemplo um inimigo que se esconde atrás de uma árvore, seus pixels não serão renderizados no frame buffer pois seus lugares serão ocupados pelos pixels da árvore.
E como o mecanismo de renderização “sabe” quais pixels serão renderizados e quais não serão? Da forma mais simples possível: se dois pixels pertencentes a dois diferentes objetos possuírem as mesmas coordenadas X e Y (ou seja, se estiverem “disputando” a mesma posição na tela), será renderizado o que tiver menor coordenada Z, já que uma coordenada Z menor corresponde a uma menor distância da tela, o que indica que o objeto a que pertence este pixel está “na frente” do outro, escondendo-o.
 |
Figura 6: Z-buffer |
Veja, na parte de cima da figura 6 (obtida na < http://upload.wikimedia.org/wikipedia/commons/4/4e/Z_buffer.svg >Wikipedia), o aspecto de uma imagem renderizada (ou seja, o conteúdo da área de memória de vídeo que denominamos frame buffer) e na parte inferior da mesma figura uma representação do conteúdo do Z-buffer, onde os pixels pertencentes aos objetos mais próximos são representados em uma cor mais escura (ou seja, cuja representação usa números menores).
Mas note que este é apenas um dos usos do Z-buffer. Pois nem todo objeto é opaco. Alguns são transparentes (veja a esfera azul da Figura 5) ou translúcidos e, neste caso, os pixels de diferentes coordenadas Z devem ser combinados de acordo com as características da transparência ou translucidez do objeto em primeiro plano. Além disso, a luz refletida por um objeto de maior coordenada Z (mais distante) pode iluminar os mais próximos “por detrás” ou de forma obliqua. E tudo isto deve ser levado em conta nos cálculos efetuados pela placa aceleradora 3D.
Finalmente, convém notar a importância do adjetivo “aceleradora”. Porque computadores são máquinas extraordinárias para fazer cálculos. E se lhes dermos tempo suficiente, serão capazes de efetuar os cálculos mais complexos. Mesmo a estrambótica calculeira necessária para gerar imagens tridimensionais.
O detalhe a considerar é a expressão “tempo suficiente”.
Minha primeira experiência com computação gráfica tridimensional foi obtida através de uma das primeiras versões do excelente programa AutoCad. Uma versão tão antiga que rodava em um velho clone de XT, sem coprocessador matemático e sem qualquer aceleração gráfica.
Um dos arquivos incluídos com o programa a guisa de demonstração era a vista tridimensional, se não me engano em wireframe, de uma belíssima obra arquitetônica (se a memória não me trai, uma catedral; mas eu tenho certeza que alguém de melhor memória que a minha também a viu e logo me corrigirá ou acrescentará os devidos detalhes nos comentários).
Para apreciá-la era preciso carregar o arquivo e esperar que a imagem fosse renderizada e exibida. E quando eu digo “esperar”, quero dizer “esperar” mesmo. Dava para ver cada linha ser traçada na tela (um pobre monitor monocromático de fósforo verde, se é que me entendem). E eram milhares de linhas. Era carregar o arquivo, ir tratar de outros afazeres e alguns (muitos) minutos mais tarde retornar para apreciar a imagem – caso já estivesse “pronta”.
E tudo isto apenas para renderizar uma cena em wireframe.
Agora deu para perceber o verdadeiro valor de uma placa aceleradora 3D e entender porque ela dispõe de tanto poder de processamento, consome tanta potência, esquenta tanto que precisa de um dissipador de calor ativo e ainda por cima usa uma substancial capacidade de memória de vídeo de alto desempenho?
É que, além de renderizar a imagem – tarefa na qual meu velho XT gastava dezenas de minutos – ela precisa gerar texturas, cuidar da iluminação, reflexos, transparências, atmosfera e tudo o mais. E fazer isto, incansavelmente, sessenta a setenta vezes por segundo.
Que dureza...
Pois na próxima coluna discorreremos sobre um exemplo prático.
Até lá
B.
Piropo