Pois bem: finalmente vamos aos Fusion.
 |
Para começar, deixemos claro que “Fusion” não é um processador. Nem mesmo uma família de processadores. Fusion é um novo conceito em arquitetura de processadores. Tanto assim que seus membros não serão designados por “CPU” (a sigla em inglês de “Unidade Central de Processamento”) nem por “GPU” (idem, de “Unidade Gráfica de Processamento”). Serão conhecidos, em inglês, pelo acrônimo APU, de “Accelerated Processing Unit” ou “Unidade de Processamento Acelerado”.
[Uma observação à margem do tema: por respeito ao nosso idioma passarei a me referir a ela em português como UPA, de Unidade de Processamento Acelerado. Bem sei que há quem não goste e prefira o uso da sigla em inglês, mas se meu amor ao bom português incomodar muito, existe por aí uma malta de colunistas e articulistas que escrevem usando uma algaravia na qual parte das palavras são em inglês e parte em (mau) português, estartam máquinas, printam documentos, upilodeiam e dounlodeiam arquivos, visitam sites, estupram nosso idioma e certamente usarão a sigla em inglês. Portanto, como ninguém é obrigado a ler o que eu escrevo, opções não faltarão a quem desejar ler mal traçadas ainda pior traçadas que estas. Em contrapartida, faço questão de usufruir do meu direito de escrever em português e, dentro de minhas limitações, em bom português. E quem não gostar que se queixe ao Paulo Couto, editor do FPCs, escolha um colunista que escreva melhor conforme seus critérios, passe a lê-lo e deixe este pobre escrevinhador em paz com sua estranha mania de respeitar o próprio idioma. Mas voltemos ao que interessa:]
Que diabos vem a ser uma UPA?
Deve ser uma coisa importante, do contrário Rick Bergman, vice-presidente e gerente geral da divisão de produtos da AMD, não se atreveria a declarar no dia 4 deste mês (janeiro de 2011, para os que lerem esta coluna no futuro) na CES de Las Vegas durante a cerimônia do lançamento das primeiras unidades comerciais que aderem a esta nova concepção que: “Acreditamos que os processadores Fusion da AMD representam simplesmente o maior avanço em processamento desde a introdução da arquitetura x86 há quarenta anos” (We believe that AMD Fusion processors are, quite simply, the greatest advancement in processing since the introduction of the x86 architecture more than forty years ago).
Perceberam o alcance da coisa? Repetindo: na opinião de Rick Bergman, Fusion representa o maior avanço em processamento desde a introdução da arquitetura x86.
Não é pouco...
Para tentar entender o que levou Mr. Bergman a fazer uma declaração tão bombástica, examinemos as informações técnicas fornecidas pela própria AMD.
Escalar x vetorial
Nas colunas anteriores desta série foram discutidos alguns aspectos pertinentes ao processamento gráfico, distinguindo-o daquilo que classificamos como “processamento de dados”, ou seja, o processamento executado, por exemplo, por um editor de textos ou programa de banco de dados. Mas em nenhum momento nos referimos à diferença essencial entre eles.
Então, vamos procurar estabelecê-la agora. Tentarei fazê-lo da forma menos formal possível, mas me perdoem os que, ainda assim, acharem o assunto demasiadamente técnico. É que há limites que impedem de simplificar demasiadamente sem o risco de tornar o tema ininteligível.
Tanto em um caso quanto em outro, o processamento consiste em efetuar transformações. E estas transformações muitas vezes abrangem um grande conjunto de dados situados em posições contiguas da memória principal (o que, em linguagem técnica, caracteriza um “vetor” que, em linguagem ainda mais técnica, corresponde a uma matriz de uma só dimensão).
No processamento de dados que não envolve gráficos, a ocorrência de operações sobre vetores não é predominante. Ciclos sucessivos envolvem, portanto, distintas operações sobre dados diferentes que podem estar armazenados em posições não contiguas da memória. Este tipo de processamento denomina-se “escalar” e os processadores a ele destinados denominam-se “processadores escalares”. São nossas velhas conhecidas UCPs.
Ocorre que mesmo os processadores escalares precisam, vez ou outra, operar sobre vetores. E quando isto ocorre eles operam sobre um dado (ou “elemento” do vetor) de cada vez. E se for preciso fazer a mesma operação em mil elementos de certo vetor – o que gerará um novo vetor de mil elementos transformados – o processador “aponta” para a posição de memória ocupada por um elemento do primeiro vetor, copia o valor ali armazenado em um dos registradores da UCP, efetua as devidas operações e transfere o resultado para a posição de memória equivalente no trecho de memória destinado ao segundo vetor. Em seguida “incrementa os ponteiros” (ou seja, “aponta” para as posições de memória subsequentes do primeiro e do segundo vetor), repete a operação e prossegue, contando, até completar mil ciclos.
O que torna processadores escalares particularmente ineficientes para este tipo de operação é o fato de que o tempo gasto para gerenciar os ponteiros, executar a contagem dos ciclos e demais operações auxiliares costuma ser muito maior do que o gasto para executar o processamento propriamente dito, ou seja, as mil transformações dos elementos do vetor. Mas este é o comportamento típico de um processador escalar, ou UCP.
Já uma UGP funciona de forma diferente. Como ela se destina principalmente a processar gráficos e os arquivos gráficos se caracterizam por um enorme número de dados similares em posições contiguas da memória principal (pense, por exemplo, em uma foto de uma pessoa sentada sobre um gramado em um dia de céu com poucas nuvens e veja quantos pixels ela contém com tons similares de verde, na faixa inferior, e de azul, na superior), a imensa maioria das operações a serem por ela executadas têm como objeto os vetores. E por isto é otimizada para trabalhar em conjunto com todos os elementos de um vetor. Em razão disto as UGPs adotam uma arquitetura radicalmente diferente das UCPs.
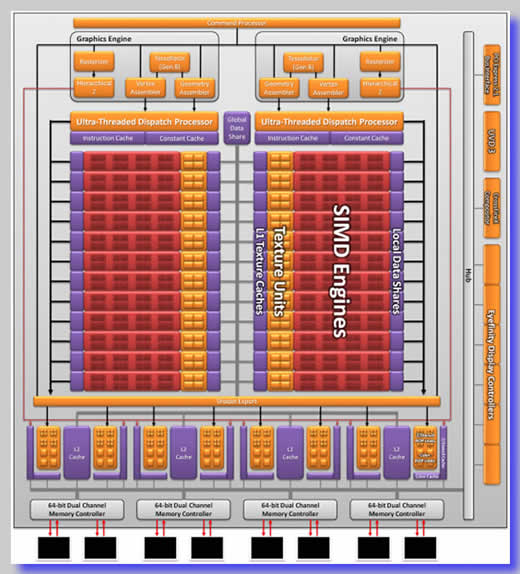 |
Figura 1: Núcleo de um processador vetorial com 24 unidades de cálculo numérico |
Este tipo de processador se distingue por sua grande capacidade de executar cálculos simultâneos sobre um conjunto de dados. No interior das UGPs mais avançadas há dezenas, por vezes centenas de unidades especificamente dedicadas a cálculos, capazes de operar simultaneamente (veja figura). Por esta razão, quando é necessário efetuar certa operação sobre todos os, digamos, mil elementos de um vetor, e a UGP dispõe de, por exemplo, cem unidades capazes de efetuar cálculos, as mil operações são distribuídas pelas cem unidades internas e todo o trabalho é cumprido em um décimo do tempo gasto para efetuar a mesma transformação usando uma UCP. E, justamente por serem concebidas para operarem principalmente sobre vetores, as UGPs são classificadas como “processadores vetoriais”.
É claro que os processadores vetoriais não operam exclusivamente sobre vetores. E também é claro que a grande melhoria no desempenho que eles proporcionam somente é alcançada quando são solicitados a executarem repetidamente operações iguais sobre vetores de grande número de elementos. Para operações escalares ou mesmo para operações vetoriais sobre vetores de pequeno número de elementos, pode-se perder mais tempo distribuindo os elementos pelas diversas unidades internas e gerenciando sua operação simultânea do que executando as transformações propriamente ditas.
Então, há casos e casos. Para processar determinados algoritmos, melhor usar processadores escalares. Para outros, processadores vetoriais. Pois nada impede que um processador vetorial, justamente aquele que conhecemos por UGP por sua otimização para processar gráficos, seja usado para realizar outros tipos de operações que não envolvam gráficos.
Misturando processos
Ou seja: embora os processadores vetoriais modernos tenham sido concebidos para processamento gráfico, há muitas situações em que eles podem acelerar consideravelmente a execução de certos algoritmos que nada têm a ver com gráficos mas cujos dados se apresentam sob a forma de vetores (lembre-se: um vetor nada mais é que uma matriz unidimensional, ou seja, uma longa “fila” de dados correlatos, em geral armazenados na memória principal em posições contiguas). E estas situações têm se apresentado com cada vez maior frequência na computação moderna. Por exemplo: vasculhar grandes bancos de dados em busca de configurações capazes de reconhecer uma impressão digital, uma fisionomia (que, como se verá adiante, tanto em um caso quanto em outro, não são tratadas como figuras, mas como um conjunto de dados numéricos), a interpretação do significado de uma sentença, o reconhecimento de voz, a detecção de uma anomalia em uma “chapa” de Raios-X e mais um monte de outras tarefas que, embora não envolvam o traçado de gráficos e a manipulação de imagens, exigem pesado processamento vetorial.
 |
Figura 2: Pontos característicos de uma impressão digital |
Veja a impressão digital exibida na figura. Nela, são marcados determinados pontos característicos. Toda impressão digital pode ser representada apenas pela determinação de alguns destes pontos e pela codificação da relação espacial entre eles. Note que esta codificação não é feita sob a forma de uma imagem, mas de uma representação numérica que nada tem a ver com a geração de um gráfico. Centenas de milhares destas representações formam um vetor. Comparar este tipo de codificação de uma impressão digital obtida “no campo” com as centenas de milhares de outras contidas no banco de dados definitivamente não é um procedimento que envolve gráficos, mas ainda assim exige uma imensa capacidade de processamento vetorial. O mesmo pode ser dito do reconhecimento de fisionomias, onde os rostos são codificados não por suas imagens gráficas, mas numericamente, através da relação espacial entre pontos característicos de cada fisionomia, como posições dos cantos da boca, dos olhos, e outros tantos elementos.
Em casos como estes, embora não se trate de manejo de imagens, as arquiteturas e ferramentas de programação convencionais, otimizadas para processamento escalar, estão longe de serem as mais eficientes. Como estas operações, embora nada tenham a ver com o processamento gráfico, envolvem transformações ou comparações entre vetores e recorrem pesadamente a processamento paralelo em múltiplas “threads”, o ideal para efetuá-las é usar um processador vetorial (“thread” é o nome técnico em inglês usado para denominar os processos individuais em que pode ser subdividida uma tarefa de processamento e que podem ser executados independente e simultaneamente por diferentes núcleos ou componentes internos do mesmo processador).
Os especialistas chamam a tecnologia usada no processamento vetorial de SIMD (“Single Instruction Multiple Data” ou única instrução, muitos dados) por sua capacidade de fazer a mesma instrução atuar simultaneamente sobre todos os elementos de um vetor, enquanto a tecnologia usada no processamento escalar recebe o nome de “SISD” (“Single Instruction Single Data” ou única instrução, único dado) por razões evidentes. Há anos trava-se um debate acirrado sobre qual delas é mais eficiente. Hoje se sabe que ambos os lados estão certos e que não se trata de escolher entre uma ou outra, mas de usar ambas, cada uma na ocasião devida. Assim, há problemas que fazem uso intensivo de cálculo numérico e que são melhor atendidos pelo processamento paralelo usando a tecnologia SIMD e outros que resultam em um desempenho mais eficiente recorrendo à tecnologia SISD. O que leva à inevitável conclusão de que, caso o processador use apenas uma delas, será extremamente eficiente em algumas ocasiões e bastante ineficiente em outras.
Para que a eficiência seja mantida sempre no mesmo patamar, a unidade de processamento deve poder recorrer a ambas as tecnologias, usando a mais eficiente conforme a tarefa.
O “pulo do gato”
No fundo, a ideia que levou ao Fusion é muito simples. Pois, considerando o que foi dito acima sobre processamento vetorial e escalar e levando em conta que nem todo processamento vetorial tem a ver com gráficos, a AMD decidiu aproveitar a evolução tecnológica que permite a fabricação de processadores multinucleares e concebeu, em uma única unidade de processamento, a inclusão tanto de núcleos otimizados para o processamento escalar quanto de núcleos otimizados para o processamento vetorial, tudo isto na mesma pastilha de silício, que também engloba diversas unidades auxiliares, como cache interno, gerenciador de memória (eliminando assim o gargalo do barramento frontal, ou USB) e até mesmo decodificadores de vídeo e controladores de barramentos PCI-E.
 |
Figura 3: Diagrama esquemático da arquitetura Fusion |
Como todos estes componentes estão, literalmente, fundidos na mesma peça de silício (ou no mesmo “die”, em inglês), sua integração é completa, permitindo que as UPAs executem as tarefas que exigem o uso de processamento convencional em seu(s) núcleo(s) escalar(es), aos quais ela se refere como “tecnologia x86”, e as tarefas que serão mais eficazmente executadas via processamento vetorial – inclusive as relativas ao processamento gráfico mas não exclusivamente – em seu(s) núcleo(s) que usa(m) uma versão avançada da tecnologia de processamento vetorial que a AMD vem aperfeiçoando desde que adquiriu o conhecimento básico específico com a aquisição da ATI há alguns anos.
Resumindo, e citando um trecho da comunicação à imprensa especializada emitida pela própria AMD: “Em seu nível mais básico, as novas Unidades de Processamento Acelerado da AMD combinam núcleos de UCP com mecanismos programáveis de processamento vetorial na mesma peça de silício. As UPAs da AMD também incluem uma variedade de elementos críticos do sistema, como controladores de memória, controladores de E/S, decodificadores de vídeo especializados, saídas para vídeo e interfaces de barramento, mas a grande vantagem destes “chips” deriva da inclusão de hardware tanto escalar quanto vetorial como elementos plenos de processamento” [At the most basic level, AMD’s new Accelerated Processing Units combine general-purpose x86 CPU cores with programmable vector processing engines on a single silicon die. AMD’s APUs also include a variety of critical system elements, including memory controllers, I/O controllers, specialized video decoders, display outputs, and bus interfaces, but real appeal of these chips stems from the inclusion of both scalar and vector hardware as full-fledged processing elements].
A chave para se entender a diferença entre as novas UPAs da AMD e tudo o que foi fabricando antes neste campo são as expressões “na mesma unidade de silício” (“on a single silicone die”) e “elementos plenos de processamento” (“full-fledged processing elements”). Isto porque não se trata meramente de incluir uma UCP e uma UGP em um mesmo encapsulamento plástico, o que já foi feito pela Intel com parco sucesso, mas de integrar diferentes núcleos especializados em processamento escalar e vetorial na mesma pastilha de silício (“die”). Também não se trata de fabricar uma unidade de processamento capaz de gerir gráficos e dados escalares em elementos independentes contidas no mesmo encapsulamento, mas de integrar tudo isto em núcleos capazes de efetuar processamento vetorial ou escalar quando um ou outro é mais eficiente, independentemente de se tratar de gráficos ou não.
Mais que isto: embora os núcleos voltados para processamento escalar (x86) e vetorial (SIMD) das novas UPAs compartilhem uma via única de acesso à memória principal, a primeira geração de membros da arquitetura Fusion divide esta memória em regiões definidas, algumas delas gerenciadas pelo sistema operacional que roda nos núcleos x86 e outras gerenciadas pelos programas que rodam nos núcleos vetoriais. Como nos sistemas que usam UPAs o controlador da memória principal está contido no interior da própria UPA, ficou fácil para a AMD implementar mecanismos de transferência em bloco que movimentam dados com grande rapidez entre estas partições de memória sem que eles transitem pelo barramento do sistema (que tradicionalmente funciona como um gargalo para este tipo de operação).
Realmente a ideia da qual derivou o Fusion é revolucionária.
Se ele será ou não “o maior avanço em processamento desde a introdução da arquitetura x86” o tempo dirá. Mas de acordo com os dados a que tive acesso, que incluem análises de desempenho, tudo indica que a Intel deve começar a se preocupar seriamente com o assunto e caprichar muito, mas muito mesmo, na nova arquitetura “Sandy Bridge” que está para vir à luz.
Digo isto porque, apesar de não estar presente ao lançamento dos novos chips – sobre os quais falaremos adiante – durante a CES, tive a oportunidade de vê-los em pleno funcionamento três meses antes, no lançamento da linha Radeon HD 6800 em Los Angeles.
E nada como uma observação de corpo presente para formar uma opinião.
Pois vou contar uma coisa pra vocês: o bicho impressiona...
B.
Piropo
